Серверный SATA/SAS RAID контроллер LSI 9267-8i купленный на тао

- Цена: 14.84$ за контроллер + 8.4$ за 4-х портовый кабель+ доставка до РФ
- Перейти в магазин
Всем привет. Сегодня я хотел бы немного рассказать о серверном RAID контроллере LSI 9267-8i, купленном на таобао, по весьма гуманной цене (на али цены на такие контроллеры выше).
Контроллер понадобился мне для организации надёжного массива RAID5, аппаратными средствами, который я хочу собрать из б/у серверных дисков, имеющих интефейс SAS. Контроллер поддерживает и более сложный в вычислительном плане RAID 6, но для домашнего использования это слишком дорого (хоть и более надёжно чем RAID5), так как надо иметь минимум 4 накопителя.
Контроллер был приобретён через посредника yoybuy.com
Почему SAS? А потому, что цены на них ниже чем на аналогичные б/у SATA диски, и как я предполагаю, находящихся примерно в одинаковом состоянии по «умотанности». Ну и SAS диски вряд ли будут использовать для видеонаблюдения, где износ очень высок, хотя и в том же Web сервере, где могли использовать SAS, он может быть не малым. Опять же вопрос, где могли использовать SAS диски больших объемов, которые мне как раз и нужны.
В крайнем случае, ввиду универсальности контроллера, всегда можно будет купить и SATA диски, если подвернётся нормальный вариант.
Сейчас я всё ещё думаю, брать ли три диска с tao, или мониторить авито, так как доставка дисков мероприятие не дешёвое, если учитывать что один 3.5 дюймовый серверный диск на 3ТБ весит около килограмма.
Один б/у SAS диск (3.5 дюйма) ёмкостью 3ТБ с сервера Dell (на самом деле сделанный Hitachi), стоит на тао в районе 22$, очень заманчиво, если бы не доставка.
Лучше вообще брать сразу 4 диска, 3 под массив и один под Hot Spare, тобишь под автоматическую горячую замену, говоря по русски. Если один диск помрёт, а вероятность этого весьма высокая, учитывая что диски будут сильно б/у, ведь в серверах они обычно не прохлаждаются, и будет заранее подготовлен подменный диск, то RAID контроллер может автоматом начать восстановление на него.
Я не планирую давать сильную нагрузку на этот массив, и вообще думаю его только изредка включать, но пока точно не решил буду ли использовать второй компьютер с контроллером, как мини хранилку, т.е. отдавать диск по гигабитной сети, через ISCSI, возможно я ограничусь только хранением бэкапов, и фото+видео контента.
Вообще у RAID 5 есть как плюсы так и минусы. Жирный плюс — более экономное расходование дискового пространства. Ёмкость виртуального диска, в случае с RAID 5, будет равна суммарной ёмкости двух дисков из трёх, т.е. будет «потеряна» под хранение «избыточности под контроль чётности» лишь ёмкость, эквивалентная ёмкости одного диска. Если взять 3 диска по 3ТБ, то итоговая ёмкость виртуального диска отдаваемого ОС, будет около 6ТБ.
К минусам RAID5 массива, можно отнести высокие требования к вычислительной способности контроллера RAID, тормознутость массива в случае отказа одного из 3-х дисков, его медленное восстановление, и возможность отказа ещё одного диска пока массив восстанавливается, из-за резко возросшей нагрузки на оставшиеся диски.
В данном случае, RAID контроллер построен на двухядерном чипе LSI2208 (именуется RoC), имеющим приличное быстродействие по RAID5 операциям по меркам аппаратных RAID контроллеров 2013-2015 годов.
Далее были ещё контроллеры на более быстром RoC LSI 3108, RAID контроллер на котором я тестировал ещё году эдак так в 2015, одним из первых в России (когда то я работал в intel, а контроллеры intel были по сути просто с наклейкой Intel, а так это был LSI, который впоследствии был поглощён компанией Broadcom, и ещё позже уже часть активов последней, ушла уже под компанию Avago).
Так вот, LSI 3108 был не сказать что прям в разы лучше LSI2208 (разве что скорость порта стала 12Гб против 6Гб), при том что LSI2208 был более ощутимо производительнее чем предшественник LSI 2108, но в разы более медленным, его назвать нельзя. Вся прибавка там была в том что LSI2208 стал двухядерным, но насколько я помню, производительность не возросла там во столько же раз как количество ядер. Сейчас вероятно вышли более новые и совершенные RoC (кому интересно загуглите), лично я перестал следить за серверным рынком уже лет так 6-7, и потерял возможность тестирования таких девайсо, а гуглить мне лениво. Ну и прошивку на контроллеры на базе LSI 3108 возможно немного оптимизировали чтобы максимально выжать всё из RoC, улучшив скорости работы массивов, но это не точно и маловероятно).
Почему именно аппаратный контроллер? Обычный SATA контроллер SAS диски попросту не увидит, и при этом можно установить и SATA диски, в том числе и SSD, задействовать технологию CacheCade (но нужен аппаратный ключик), с помощью которой можно организовать кэширование часто используемых данных на SSD (кстати у intel была неплохая программка, занимающяяся аналогичной деятельностью, и на неё я тоже лет 8 назад писал первый в рунете русскоязычный обзор, на ресурсе Intel IT Galaxy, которого уже давно нет).
На моём контроллере уже стоит какой то ключ, но у меня пока не было желания разбираться для чего именно он предназначен.
Так же, у контроллера есть RAM кэш (в моём случае урезанный, всего 512МБ, а для контролеров с RoC LSI2208 обычно характерен 1ГБ кэша), и 8 внутренних портов, на 6Гб/c каждый.
Вообще, обычно бывает 4/8/16 портов, если надо больше, то применяют специальные расширители.
Кстати, мне пришлось докупить дорогущий кабель (цены не малой, почти как сам RAID контроллер), что бы c Mini-SAS (SFF-8087) подключить к контроллеру напрямую 4 диска и питание. В серверах, диски обычно подключаются и питаются через плату Backplane, от которого уже идёт кабель до контроллера.
Ну и вообще, у меня, немного зачесались руки «вспомнить молодость», когда часто приходилось помогать людям управляться с этими самыми RAID контроллерами, и подбирать их под конкретные задачи, собственно и был заказан такой контроллер, сейчас доступный по цене многим.
Кстати, фирма LSI (ныне Avago) это по сути один из лидеров рынка серверных RAID контроллеров. Из популярных, ещё есть RAID контроллеры фирмы Adaptec.
Думаю, что вводной информации достаточно, перейдём к самому контроллеру.
Внешний вид контроллера
Контроллер и кабель пришли в следующем виде:
 Контроллер надёжно уложен в пластиковый кейс, новые контроллеры как раз поставляются в таком же.
Контроллер надёжно уложен в пластиковый кейс, новые контроллеры как раз поставляются в таком же.
На контроллере видна новодельная пломба, и установленный ключ.
 На оборотной стороне контроллера всё в норме, и не сказать что он сильно б/у.
На оборотной стороне контроллера всё в норме, и не сказать что он сильно б/у.
 Судя по маркировке N8103-150, изначально он шёл вероятно с сервером/рабочей станцией от NEC, Там же, приведены и его характеристики (объём кэша, поддержка уровней массива).
Судя по маркировке N8103-150, изначально он шёл вероятно с сервером/рабочей станцией от NEC, Там же, приведены и его характеристики (объём кэша, поддержка уровней массива).
С подключенным кабелем фото вышло не чётким, но в целом видно что есть ещё свободный, 4-х портовый коннектор.
 Как видим, питание на диски, от БП подаётся через 4-х пиновые molex коннекторы. К диску уже подсоединяется совмещённый коннектор, по сути эдакая эмуляция Backplane.
Как видим, питание на диски, от БП подаётся через 4-х пиновые molex коннекторы. К диску уже подсоединяется совмещённый коннектор, по сути эдакая эмуляция Backplane.
При инициализации, контроллер определяется так:
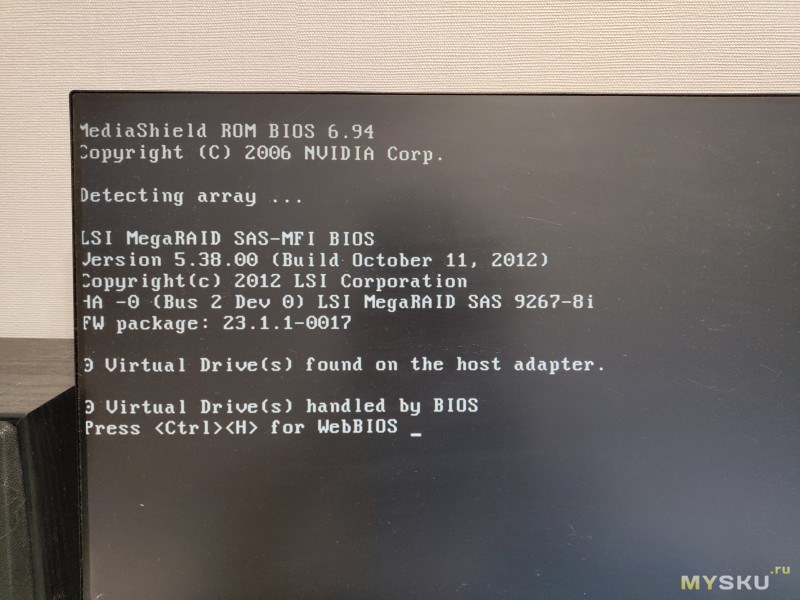 Ещё отмечу тот факт, что все серверные контроллеры рассчитаны под постоянный обдув внутри сервера, так как и если его не обдувать, то температура радиатора системы охлаждения RoC LSI2208 (весь горяч), даже при незначительной нагрузке достигает 70+ градусов (у меня в открытом корпусе именно так), что не приемлемо.
Ещё отмечу тот факт, что все серверные контроллеры рассчитаны под постоянный обдув внутри сервера, так как и если его не обдувать, то температура радиатора системы охлаждения RoC LSI2208 (весь горяч), даже при незначительной нагрузке достигает 70+ градусов (у меня в открытом корпусе именно так), что не приемлемо.
Вообще, контроллер у меня без проблем заработал на древней дестопной плате Gigabyte, где PCI-E ещё Gen 1, но для тестов самое то, учитывая что контроллер воткнут в X16 разъём, и сам имеет 8 разведённых линий PCI-E.
 Единственное, я не смог корректно произвести настройки в BIOS контроллера, настраивал его в итоге через ОС (утилита с GUI: LSI MSM и консольная утилита: MEGACLI).
Единственное, я не смог корректно произвести настройки в BIOS контроллера, настраивал его в итоге через ОС (утилита с GUI: LSI MSM и консольная утилита: MEGACLI).
Тестирование
Переходим к самому интересному, к тестированию.
Так как нужного количества свободных дисков для поднятия массива RAID5 у меня пока нет, я протестирую контроллер и его возможности с помощью SSD от Zotac, недавно побывавшего у меня на обзоре.
Подключаю SSD к одному из портов контроллера.
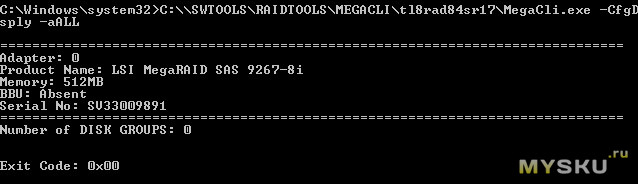
 Сначала я поставил консоль MEGACLI, там корректно определяется контроллер и подключенный накопитель, выводя информацию о его адресе (она нужна для выполнения дальнейших комманд).
Сначала я поставил консоль MEGACLI, там корректно определяется контроллер и подключенный накопитель, выводя информацию о его адресе (она нужна для выполнения дальнейших комманд).
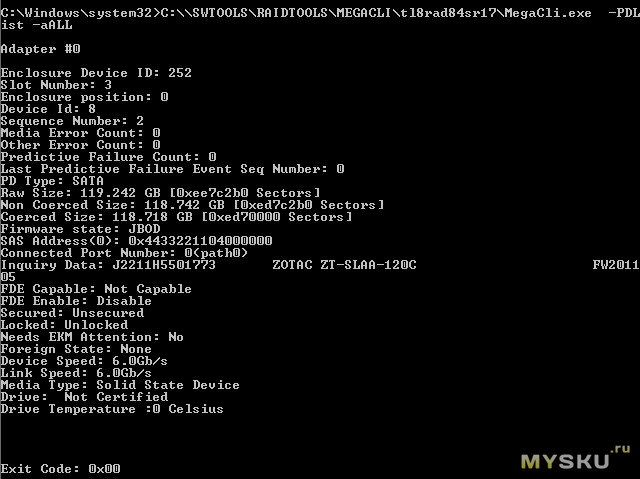 Контроллер автоматом подтянул SSD в режиме JBOD, т.е как HBA адаптер, по сути на прямую отдавая его ОС. В ОС он инициализируется точно так же, как если бы был подключен к материнке.
Контроллер автоматом подтянул SSD в режиме JBOD, т.е как HBA адаптер, по сути на прямую отдавая его ОС. В ОС он инициализируется точно так же, как если бы был подключен к материнке.
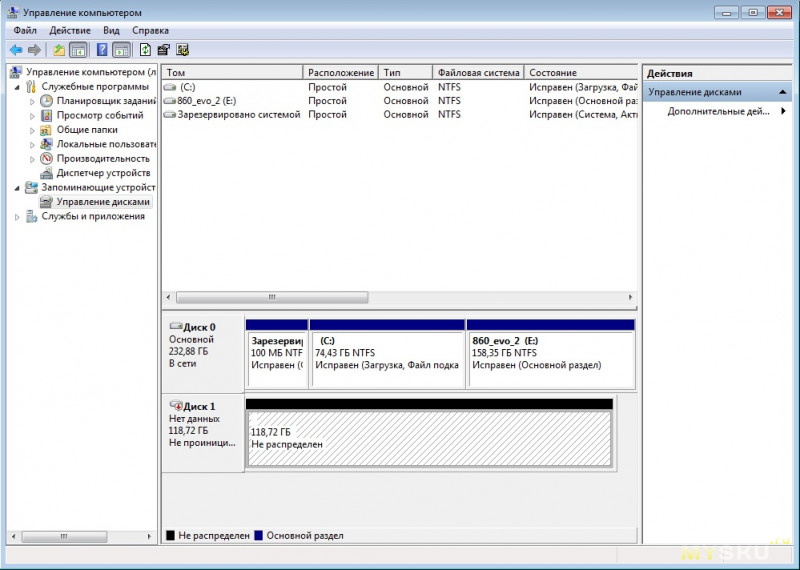 В этом режиме кэши контроллера не активны.
В этом режиме кэши контроллера не активны.
Произведём замер скорости в этом режиме, на чистом SSD.
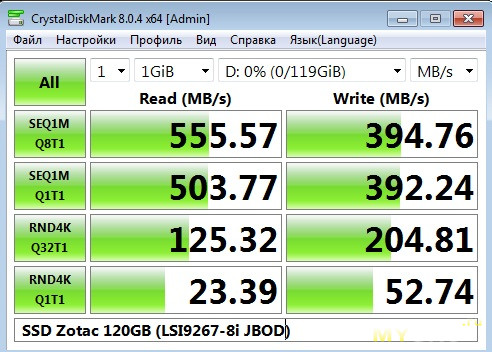 Далее я пробовал через консоль поднять на накопителе RAID 0, так как его можно собирать из одного накопителя. Но что то не срослось, возможно надо было сначала перевести диск в несконфигурированный.
Далее я пробовал через консоль поднять на накопителе RAID 0, так как его можно собирать из одного накопителя. Но что то не срослось, возможно надо было сначала перевести диск в несконфигурированный.
 Я решил не мучаться с командами и поставить оболочку MSM, в которой всё видно наглядно. В нынешние времена, с российского IP скачать её не удалось, пришлось качать установщик через зарубежную проксю. Вообще, данная утилита мультисерверная, с помощью неё можно управлять RAID контроллерами на разных серверах с одного ПК. В моём случае, я через утилиту управляю контроллером с того же ПК, где стоит сам контроллер.
Я решил не мучаться с командами и поставить оболочку MSM, в которой всё видно наглядно. В нынешние времена, с российского IP скачать её не удалось, пришлось качать установщик через зарубежную проксю. Вообще, данная утилита мультисерверная, с помощью неё можно управлять RAID контроллерами на разных серверах с одного ПК. В моём случае, я через утилиту управляю контроллером с того же ПК, где стоит сам контроллер.
Основное окно программы выглядит так:
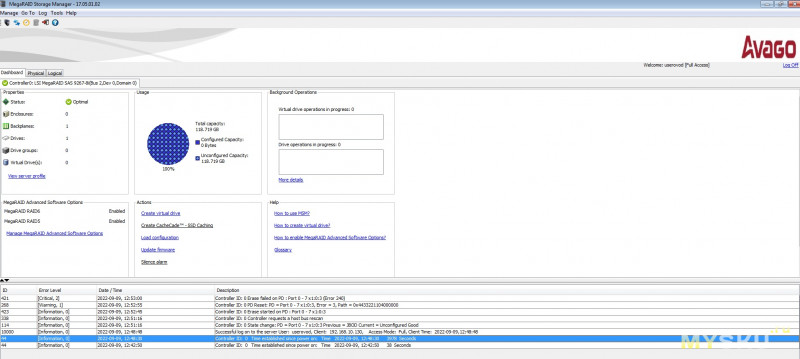 На основном окне доступен ряд важных опций по управлению, виден журнал событий, а так же информация по конфигурации массива и накопителей.
На основном окне доступен ряд важных опций по управлению, виден журнал событий, а так же информация по конфигурации массива и накопителей.
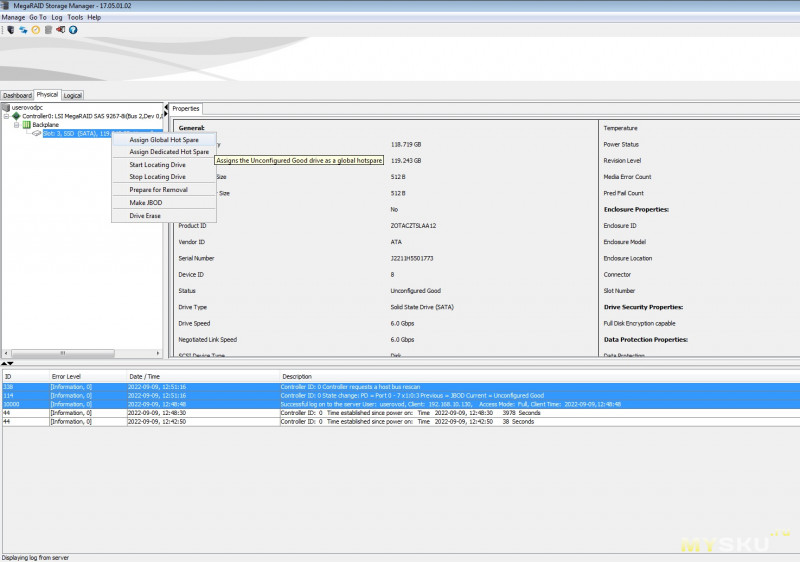
Далее есть вкладка с физическим видом, т.е. там наглядно отображено как и куда подключены накопители. Конкретно, на скриншоте ниже, показан никак не сконфигурированный накопитель, т.е. в ОС он не выдаётся.
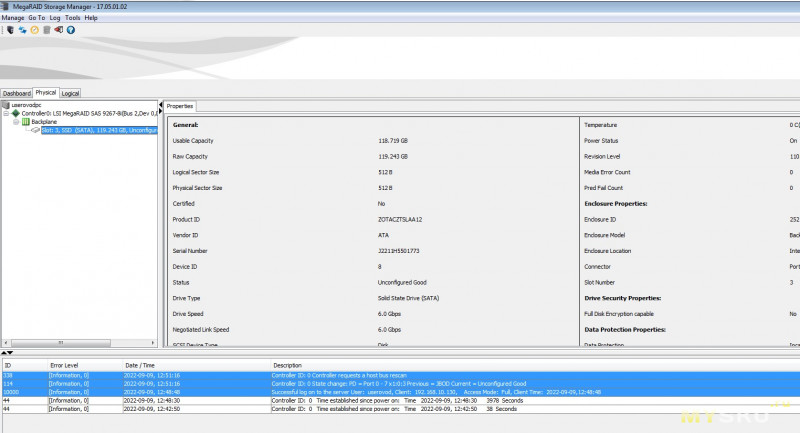 Здесь же мы можем произвести ряд операций с накопителем: очистка, задать как его подменный, подготовить к удалению из массива и т.д., в том числе отдать его ОС в режиме JBOD.
Здесь же мы можем произвести ряд операций с накопителем: очистка, задать как его подменный, подготовить к удалению из массива и т.д., в том числе отдать его ОС в режиме JBOD.
 На логическом уровне, мы уже видим параметры виртуального диска, тобишь нашего массива, если он был создан.
На логическом уровне, мы уже видим параметры виртуального диска, тобишь нашего массива, если он был создан.
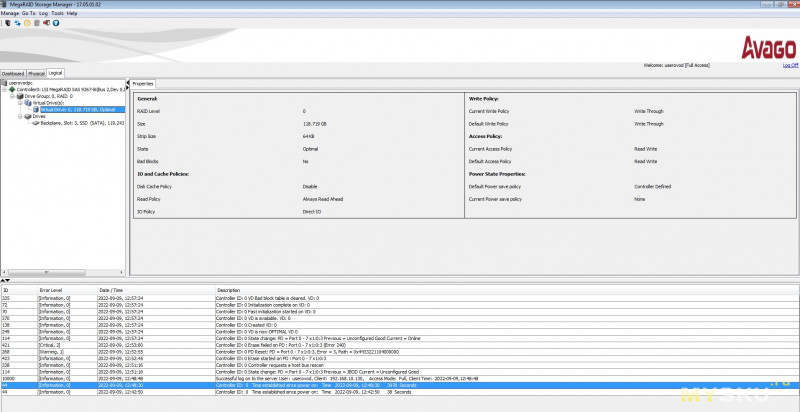 Здесь же можно поменять их. Единственное, надо быть аккуратным с включением RAM кэша, ведь при пропадании питания то что не успело сбросится на диск в режиме кэширования записи, превратится в тыкву.
Здесь же можно поменять их. Единственное, надо быть аккуратным с включением RAM кэша, ведь при пропадании питания то что не успело сбросится на диск в режиме кэширования записи, превратится в тыкву.
Поэтому к контроллеру должна идти специальная батарея BBU (литиевый акб+контроллер, которая имеет свойство помирать года через 3, видимо от температур внутри сервера), либо такая же, но «вечная» батарея уже на суперконденсаторах (ионисторах), она была в разы дороже обычной «умирающей» от времени батареи, и брали её конечно же хуже, и вероятно не все вообще знали про неё, лет 7 назад, когда я работал с такими контроллерами.
У меня «батарейки» нет, и UPS так же не предвидится, поэтому кэш на запись (write back) я включать не буду (да и не даст мне контроллер), ограничась только кэшем на чтение, он же «Write-through caching».
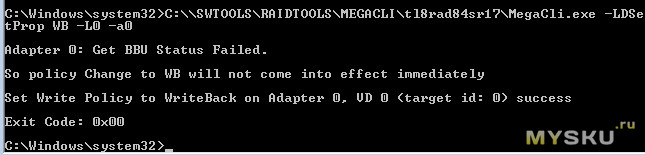
Пробуем включить кэш на запись через консоль, так как через утилиту MSM вообще нет данной опции, и не спроста.
Утилита предупреждает что BBU у нас нет, и так делать не хорошо, но политику кэша всё таки сменится, после того как мы накинем батарею. Поэтому довольствуемся только кэшом на чтение. Эдакая защита от дурака, или маркетинговый расчёт? так как батареи BBU всегда были дорогими, представляю сколько она новая стоит сейчас.
 Как вариант, можно поискать дохлую на авито, и попробовать её оживить методом «колхозинга» банок формата 18650, но не факт что контроллер батареи даст выполнить подмену, надо гуглить или тестить самому, пока не знаю буду ли я этим заниматься.
Как вариант, можно поискать дохлую на авито, и попробовать её оживить методом «колхозинга» банок формата 18650, но не факт что контроллер батареи даст выполнить подмену, надо гуглить или тестить самому, пока не знаю буду ли я этим заниматься.
Создадим RAID0 (виртуальный диск):
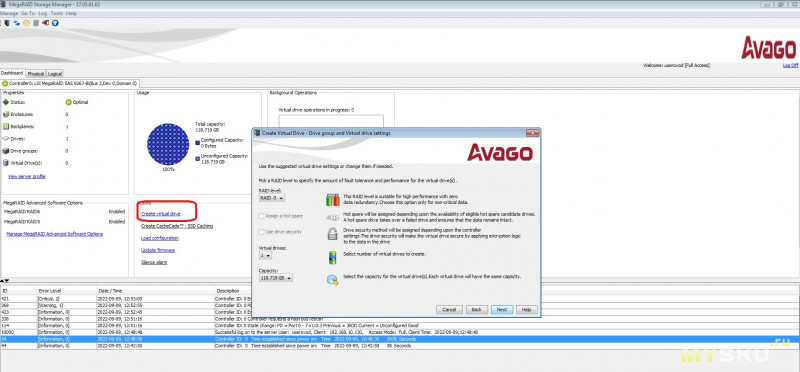 Выбираем уровень массива, и накопители члены массива.
Выбираем уровень массива, и накопители члены массива.
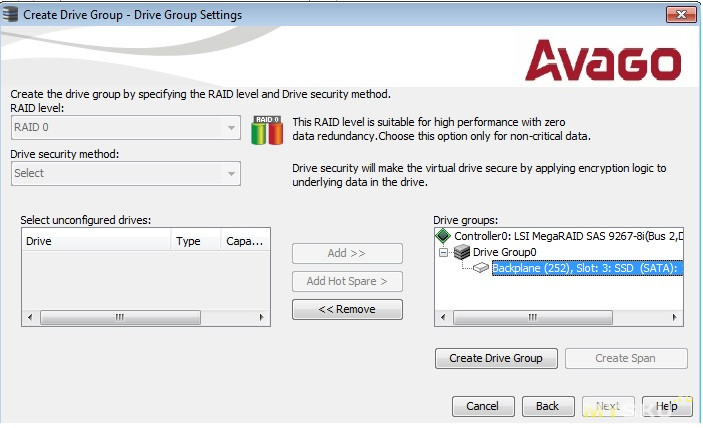
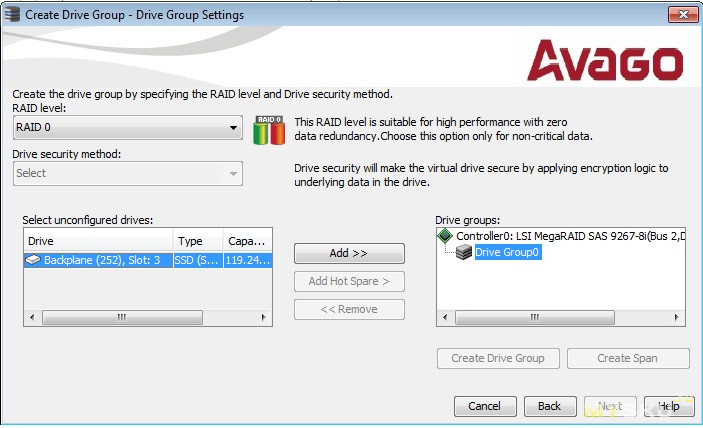 Создаём дисковую группу
Создаём дисковую группу
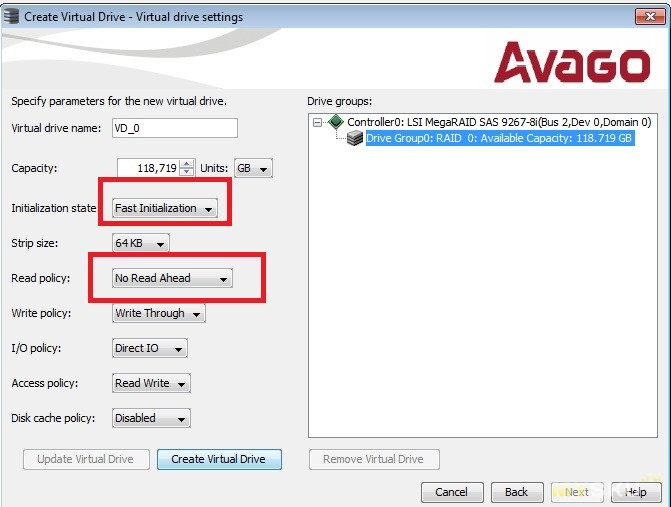
 Задаём настройки. Тут я поставил быструю инициализацию, хотя, можно было её не делать вообще, размер страйпа я оставил по умолчанию равным 64К, опцию read ahead отключаем, так как у нас SSD, и она всё же более актуальна для HDD, у которых низкая скорость вывода по мелким одиночным блокам. При активации этой опции, контроллер будет читать ещё не запрошенные данные заранее (на перёд), вместе с запрошенными в текущий момент данными, предполагая что к ним так же вскоре могут обратиться, так как они находятся рядом с запрошенной областью, и иногда это может быть выгодно, и во времена когда не были распространены SSD, «хватались» и за такую возможность оптимизации ввода/вывода (объяснил как смог). Дальше идут настройки по кэшам и политике доступа к данным. Кэш ввода/вывода и собственные кэши накопителя выключаем.
Задаём настройки. Тут я поставил быструю инициализацию, хотя, можно было её не делать вообще, размер страйпа я оставил по умолчанию равным 64К, опцию read ahead отключаем, так как у нас SSD, и она всё же более актуальна для HDD, у которых низкая скорость вывода по мелким одиночным блокам. При активации этой опции, контроллер будет читать ещё не запрошенные данные заранее (на перёд), вместе с запрошенными в текущий момент данными, предполагая что к ним так же вскоре могут обратиться, так как они находятся рядом с запрошенной областью, и иногда это может быть выгодно, и во времена когда не были распространены SSD, «хватались» и за такую возможность оптимизации ввода/вывода (объяснил как смог). Дальше идут настройки по кэшам и политике доступа к данным. Кэш ввода/вывода и собственные кэши накопителя выключаем.
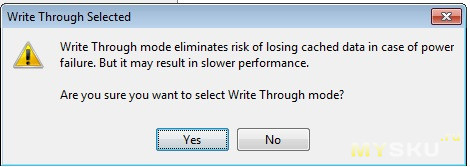
 Программа почему то предупреждает по поводу кэша Write-through, который не должен как то повлиять на целость и актуальность данных на физических дисках в случае потери питания.
Программа почему то предупреждает по поводу кэша Write-through, который не должен как то повлиять на целость и актуальность данных на физических дисках в случае потери питания.
 Видим все настройки созданного виртуального диска (массива), там же можем их изменить, при необходимости.
Видим все настройки созданного виртуального диска (массива), там же можем их изменить, при необходимости.
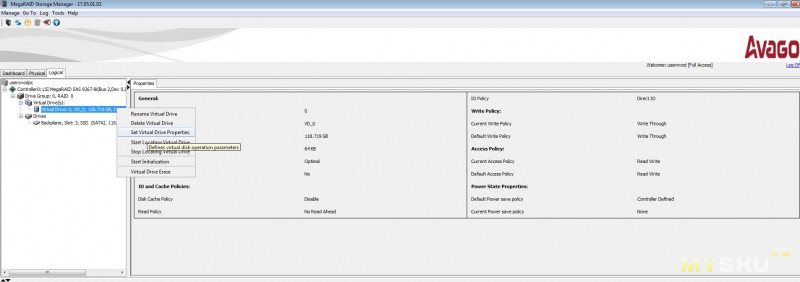 Инициализируем виртуальный диск в ОС точно так же как обычный накопитель, и проводим тест.
Инициализируем виртуальный диск в ОС точно так же как обычный накопитель, и проводим тест.
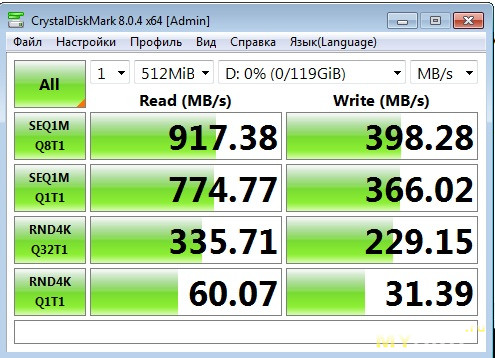
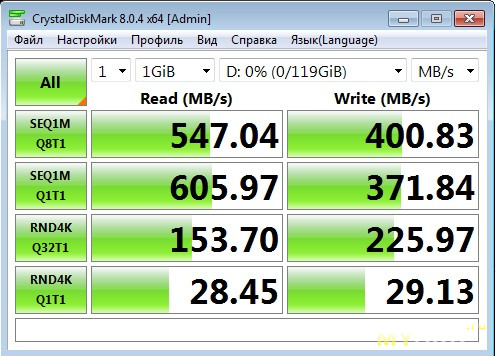 Как видим, размере тестового файла в 1ГБ, скорость выше чем в режиме JBOD, значит кэш работает. Теперь проверим его же, но с размером тестового файла в 512МБ, чтобы целиком влезть в размер кэша. При таком раскладе результат впечатляет, особенно по 4К одиночному чтению (не каждый NVMe SSD так сможет), но увы, это только на 512МБ файле, пока он влезает в RAM кэш. А вот по записи 4К результаты не особо впечатляют, по сравнению с режимом JBOD.
Как видим, размере тестового файла в 1ГБ, скорость выше чем в режиме JBOD, значит кэш работает. Теперь проверим его же, но с размером тестового файла в 512МБ, чтобы целиком влезть в размер кэша. При таком раскладе результат впечатляет, особенно по 4К одиночному чтению (не каждый NVMe SSD так сможет), но увы, это только на 512МБ файле, пока он влезает в RAM кэш. А вот по записи 4К результаты не особо впечатляют, по сравнению с режимом JBOD.
Ну и не забываем что есть софтовые RAM диски, также дающие хорошие скорости, реализуемые программно с помощью специализированных утилит, на базе ОЗУ ПК, для ряда задач можно успешно использовать и их, но надо иметь хороший процессор для «переварки» всего этого.
На этом всё, выводы можете сделать сами, возможно кому то так же понадобится создать массив данных для домашних нужд, с помощью относительно недорого, серверного RAID контроллера от LSI (ныне Avago), и данный обзор послужит «отправной» точкой для этого.
Контроллер понадобился мне для организации надёжного массива RAID5, аппаратными средствами, который я хочу собрать из б/у серверных дисков, имеющих интефейс SAS. Контроллер поддерживает и более сложный в вычислительном плане RAID 6, но для домашнего использования это слишком дорого (хоть и более надёжно чем RAID5), так как надо иметь минимум 4 накопителя.
Контроллер был приобретён через посредника yoybuy.com
Почему SAS? А потому, что цены на них ниже чем на аналогичные б/у SATA диски, и как я предполагаю, находящихся примерно в одинаковом состоянии по «умотанности». Ну и SAS диски вряд ли будут использовать для видеонаблюдения, где износ очень высок, хотя и в том же Web сервере, где могли использовать SAS, он может быть не малым. Опять же вопрос, где могли использовать SAS диски больших объемов, которые мне как раз и нужны.
В крайнем случае, ввиду универсальности контроллера, всегда можно будет купить и SATA диски, если подвернётся нормальный вариант.
Сейчас я всё ещё думаю, брать ли три диска с tao, или мониторить авито, так как доставка дисков мероприятие не дешёвое, если учитывать что один 3.5 дюймовый серверный диск на 3ТБ весит около килограмма.
Один б/у SAS диск (3.5 дюйма) ёмкостью 3ТБ с сервера Dell (на самом деле сделанный Hitachi), стоит на тао в районе 22$, очень заманчиво, если бы не доставка.
Лучше вообще брать сразу 4 диска, 3 под массив и один под Hot Spare, тобишь под автоматическую горячую замену, говоря по русски. Если один диск помрёт, а вероятность этого весьма высокая, учитывая что диски будут сильно б/у, ведь в серверах они обычно не прохлаждаются, и будет заранее подготовлен подменный диск, то RAID контроллер может автоматом начать восстановление на него.
Я не планирую давать сильную нагрузку на этот массив, и вообще думаю его только изредка включать, но пока точно не решил буду ли использовать второй компьютер с контроллером, как мини хранилку, т.е. отдавать диск по гигабитной сети, через ISCSI, возможно я ограничусь только хранением бэкапов, и фото+видео контента.
Вообще у RAID 5 есть как плюсы так и минусы. Жирный плюс — более экономное расходование дискового пространства. Ёмкость виртуального диска, в случае с RAID 5, будет равна суммарной ёмкости двух дисков из трёх, т.е. будет «потеряна» под хранение «избыточности под контроль чётности» лишь ёмкость, эквивалентная ёмкости одного диска. Если взять 3 диска по 3ТБ, то итоговая ёмкость виртуального диска отдаваемого ОС, будет около 6ТБ.
К минусам RAID5 массива, можно отнести высокие требования к вычислительной способности контроллера RAID, тормознутость массива в случае отказа одного из 3-х дисков, его медленное восстановление, и возможность отказа ещё одного диска пока массив восстанавливается, из-за резко возросшей нагрузки на оставшиеся диски.
В данном случае, RAID контроллер построен на двухядерном чипе LSI2208 (именуется RoC), имеющим приличное быстродействие по RAID5 операциям по меркам аппаратных RAID контроллеров 2013-2015 годов.
Далее были ещё контроллеры на более быстром RoC LSI 3108, RAID контроллер на котором я тестировал ещё году эдак так в 2015, одним из первых в России (когда то я работал в intel, а контроллеры intel были по сути просто с наклейкой Intel, а так это был LSI, который впоследствии был поглощён компанией Broadcom, и ещё позже уже часть активов последней, ушла уже под компанию Avago).
Так вот, LSI 3108 был не сказать что прям в разы лучше LSI2208 (разве что скорость порта стала 12Гб против 6Гб), при том что LSI2208 был более ощутимо производительнее чем предшественник LSI 2108, но в разы более медленным, его назвать нельзя. Вся прибавка там была в том что LSI2208 стал двухядерным, но насколько я помню, производительность не возросла там во столько же раз как количество ядер. Сейчас вероятно вышли более новые и совершенные RoC (кому интересно загуглите), лично я перестал следить за серверным рынком уже лет так 6-7, и потерял возможность тестирования таких девайсо, а гуглить мне лениво. Ну и прошивку на контроллеры на базе LSI 3108 возможно немного оптимизировали чтобы максимально выжать всё из RoC, улучшив скорости работы массивов, но это не точно и маловероятно).
Почему именно аппаратный контроллер? Обычный SATA контроллер SAS диски попросту не увидит, и при этом можно установить и SATA диски, в том числе и SSD, задействовать технологию CacheCade (но нужен аппаратный ключик), с помощью которой можно организовать кэширование часто используемых данных на SSD (кстати у intel была неплохая программка, занимающяяся аналогичной деятельностью, и на неё я тоже лет 8 назад писал первый в рунете русскоязычный обзор, на ресурсе Intel IT Galaxy, которого уже давно нет).
На моём контроллере уже стоит какой то ключ, но у меня пока не было желания разбираться для чего именно он предназначен.
Так же, у контроллера есть RAM кэш (в моём случае урезанный, всего 512МБ, а для контролеров с RoC LSI2208 обычно характерен 1ГБ кэша), и 8 внутренних портов, на 6Гб/c каждый.
Вообще, обычно бывает 4/8/16 портов, если надо больше, то применяют специальные расширители.
Кстати, мне пришлось докупить дорогущий кабель (цены не малой, почти как сам RAID контроллер), что бы c Mini-SAS (SFF-8087) подключить к контроллеру напрямую 4 диска и питание. В серверах, диски обычно подключаются и питаются через плату Backplane, от которого уже идёт кабель до контроллера.
Ну и вообще, у меня, немного зачесались руки «вспомнить молодость», когда часто приходилось помогать людям управляться с этими самыми RAID контроллерами, и подбирать их под конкретные задачи, собственно и был заказан такой контроллер, сейчас доступный по цене многим.
Кстати, фирма LSI (ныне Avago) это по сути один из лидеров рынка серверных RAID контроллеров. Из популярных, ещё есть RAID контроллеры фирмы Adaptec.
Думаю, что вводной информации достаточно, перейдём к самому контроллеру.
Внешний вид контроллера
Контроллер и кабель пришли в следующем виде:
Контроллер надёжно уложен в пластиковый кейс, новые контроллеры как раз поставляются в таком же.На контроллере видна новодельная пломба, и установленный ключ.
На оборотной стороне контроллера всё в норме, и не сказать что он сильно б/у.Судя по маркировке N8103-150, изначально он шёл вероятно с сервером/рабочей станцией от NEC, Там же, приведены и его характеристики (объём кэша, поддержка уровней массива).С подключенным кабелем фото вышло не чётким, но в целом видно что есть ещё свободный, 4-х портовый коннектор.
Как видим, питание на диски, от БП подаётся через 4-х пиновые molex коннекторы. К диску уже подсоединяется совмещённый коннектор, по сути эдакая эмуляция Backplane.При инициализации, контроллер определяется так:
Ещё отмечу тот факт, что все серверные контроллеры рассчитаны под постоянный обдув внутри сервера, так как и если его не обдувать, то температура радиатора системы охлаждения RoC LSI2208 (весь горяч), даже при незначительной нагрузке достигает 70+ градусов (у меня в открытом корпусе именно так), что не приемлемо.Вообще, контроллер у меня без проблем заработал на древней дестопной плате Gigabyte, где PCI-E ещё Gen 1, но для тестов самое то, учитывая что контроллер воткнут в X16 разъём, и сам имеет 8 разведённых линий PCI-E.
Единственное, я не смог корректно произвести настройки в BIOS контроллера, настраивал его в итоге через ОС (утилита с GUI: LSI MSM и консольная утилита: MEGACLI).Тестирование
Переходим к самому интересному, к тестированию.
Так как нужного количества свободных дисков для поднятия массива RAID5 у меня пока нет, я протестирую контроллер и его возможности с помощью SSD от Zotac, недавно побывавшего у меня на обзоре.
Подключаю SSD к одному из портов контроллера.
Сначала я поставил консоль MEGACLI, там корректно определяется контроллер и подключенный накопитель, выводя информацию о его адресе (она нужна для выполнения дальнейших комманд).Контроллер автоматом подтянул SSD в режиме JBOD, т.е как HBA адаптер, по сути на прямую отдавая его ОС. В ОС он инициализируется точно так же, как если бы был подключен к материнке.В этом режиме кэши контроллера не активны.Произведём замер скорости в этом режиме, на чистом SSD.
Далее я пробовал через консоль поднять на накопителе RAID 0, так как его можно собирать из одного накопителя. Но что то не срослось, возможно надо было сначала перевести диск в несконфигурированный. Я решил не мучаться с командами и поставить оболочку MSM, в которой всё видно наглядно. В нынешние времена, с российского IP скачать её не удалось, пришлось качать установщик через зарубежную проксю. Вообще, данная утилита мультисерверная, с помощью неё можно управлять RAID контроллерами на разных серверах с одного ПК. В моём случае, я через утилиту управляю контроллером с того же ПК, где стоит сам контроллер.Основное окно программы выглядит так:
На основном окне доступен ряд важных опций по управлению, виден журнал событий, а так же информация по конфигурации массива и накопителей.Далее есть вкладка с физическим видом, т.е. там наглядно отображено как и куда подключены накопители. Конкретно, на скриншоте ниже, показан никак не сконфигурированный накопитель, т.е. в ОС он не выдаётся.
Здесь же мы можем произвести ряд операций с накопителем: очистка, задать как его подменный, подготовить к удалению из массива и т.д., в том числе отдать его ОС в режиме JBOD.На логическом уровне, мы уже видим параметры виртуального диска, тобишь нашего массива, если он был создан. Здесь же можно поменять их. Единственное, надо быть аккуратным с включением RAM кэша, ведь при пропадании питания то что не успело сбросится на диск в режиме кэширования записи, превратится в тыкву. Поэтому к контроллеру должна идти специальная батарея BBU (литиевый акб+контроллер, которая имеет свойство помирать года через 3, видимо от температур внутри сервера), либо такая же, но «вечная» батарея уже на суперконденсаторах (ионисторах), она была в разы дороже обычной «умирающей» от времени батареи, и брали её конечно же хуже, и вероятно не все вообще знали про неё, лет 7 назад, когда я работал с такими контроллерами.
У меня «батарейки» нет, и UPS так же не предвидится, поэтому кэш на запись (write back) я включать не буду (да и не даст мне контроллер), ограничась только кэшем на чтение, он же «Write-through caching».
Пробуем включить кэш на запись через консоль, так как через утилиту MSM вообще нет данной опции, и не спроста.
Утилита предупреждает что BBU у нас нет, и так делать не хорошо, но политику кэша всё таки сменится, после того как мы накинем батарею. Поэтому довольствуемся только кэшом на чтение. Эдакая защита от дурака, или маркетинговый расчёт? так как батареи BBU всегда были дорогими, представляю сколько она новая стоит сейчас.
Как вариант, можно поискать дохлую на авито, и попробовать её оживить методом «колхозинга» банок формата 18650, но не факт что контроллер батареи даст выполнить подмену, надо гуглить или тестить самому, пока не знаю буду ли я этим заниматься.Создадим RAID0 (виртуальный диск):
Выбираем уровень массива, и накопители члены массива.Создаём дисковую группуЗадаём настройки. Тут я поставил быструю инициализацию, хотя, можно было её не делать вообще, размер страйпа я оставил по умолчанию равным 64К, опцию read ahead отключаем, так как у нас SSD, и она всё же более актуальна для HDD, у которых низкая скорость вывода по мелким одиночным блокам. При активации этой опции, контроллер будет читать ещё не запрошенные данные заранее (на перёд), вместе с запрошенными в текущий момент данными, предполагая что к ним так же вскоре могут обратиться, так как они находятся рядом с запрошенной областью, и иногда это может быть выгодно, и во времена когда не были распространены SSD, «хватались» и за такую возможность оптимизации ввода/вывода (объяснил как смог). Дальше идут настройки по кэшам и политике доступа к данным. Кэш ввода/вывода и собственные кэши накопителя выключаем.Программа почему то предупреждает по поводу кэша Write-through, который не должен как то повлиять на целость и актуальность данных на физических дисках в случае потери питания.Видим все настройки созданного виртуального диска (массива), там же можем их изменить, при необходимости.Инициализируем виртуальный диск в ОС точно так же как обычный накопитель, и проводим тест.Как видим, размере тестового файла в 1ГБ, скорость выше чем в режиме JBOD, значит кэш работает. Теперь проверим его же, но с размером тестового файла в 512МБ, чтобы целиком влезть в размер кэша. При таком раскладе результат впечатляет, особенно по 4К одиночному чтению (не каждый NVMe SSD так сможет), но увы, это только на 512МБ файле, пока он влезает в RAM кэш. А вот по записи 4К результаты не особо впечатляют, по сравнению с режимом JBOD.Ну и не забываем что есть софтовые RAM диски, также дающие хорошие скорости, реализуемые программно с помощью специализированных утилит, на базе ОЗУ ПК, для ряда задач можно успешно использовать и их, но надо иметь хороший процессор для «переварки» всего этого.
На этом всё, выводы можете сделать сами, возможно кому то так же понадобится создать массив данных для домашних нужд, с помощью относительно недорого, серверного RAID контроллера от LSI (ныне Avago), и данный обзор послужит «отправной» точкой для этого.
| +40 |
10903
54
|
| +125 |
15019
82
|
Самые обсуждаемые обзоры
| +20 |
1040
37
|
| +52 |
1955
28
|
Плюс сам SSD должен поддерживать DRAT, чтобы на этих контроллерах в HBA режиме работал TRIM.
Видел SSD диски, которые без полного инита входили в строй, но потом уходили через время. Если делать полный инит, то такие кандидаты отпадают сразу.
Бывает критично, если сайт далеко и ты там бываешь не часто.
это мутная лотерея.
Скорее проиграешь, чем выиграешь.
Когда начался только вирус-19 я у местного рецикляжника купил за 300 бачей канадских кислородный концентратор на 10л в минуту. Увы пригодился.
что это за зверь такой неведомый? 3.5" диски половинной высоты никогда даже килограмм не весили — нечему в этом обьеме столько весить.
все современные 3.5"/sas ничем кроме платы контроллера от sata собратьев не отличаются и сами по себе весят обычные ~500-700г.
хотя сама идея набирать малообьемных неликвидов в неизвестном состоянии и исходно, и тем более после транспортировки представляется весьма сомнительной.
p.s. хотя вспоминается история, как в комплекте к ssd добрый продавец приложил салазки весом больше самого ssd, а размером в разы больше, в итоге посредник взял за пересылку больше, чем стоил сам диск. но для обычного винта такая ситуация представляется маловероятной.
они не менее бодро пухнут и дохнут, нежели литий.
А вообще, если вы планируете делать 5-й рейд из трех дисков и 4-й ставить для hot spare, а диски сильно б/у, подумайте, может лучше сделать 6-й рейд из 4-х дисков, а 5-й диск приобрести на замену и его держать в шкафу?
Мы бежим в магазин, берем новый винт, тыкаем его в корзину — и получаем жутко тормозной ребилд с полной нагрузкой на винты (по чтению) и проц контроллера (ограниченная производительность, выше головы не прыгнешь). Здоровья такая нагрузка винтам не прибавит, а тут они у нас уже на грани (по износу). Есть весьма ненулевая вероятность что при ребилде (под нагрузкой) вылетит следующий винт и весь массив превратиться в тыкву. На разношерстных винтах вероятность немного поменьше, но тоже имеет быть место.
Ну и:
Все люди делятся на две категории — те кто знает, что нужно белать бекап, и те — кто уже сделал.
Все остальные оценки «сколько проживет» — это как воду у Кашпировского заряжали…
Даже без внешнего кэша шансы словить Write hole без UPS не столь уж и малые, у дисков-то свой кэш.
И если в ZFS (и некоторых других проприентарных решениях) есть контрольные суммы на все данные (а не только метаданные), то в обычном Raid нет ничего. Хлоп и развалился массив.
по умолчанию WB контроллера выключено, и WB для накопителей — тоже.
Потому шанс не записать посмертно — околонулевой
С одиночным диском проще, с массивом всё становится веселее.
Либо же рейд карты ждут коммита из дискового кэша и только тогда убивают дату из своего защищенного кэша.
так что, по-хорошему, UPS + аккум на кэш контроллера, если таковой имеется.
… можно построить 15 мостов…
Я всего лишь парирую пассаж:
Хотите пример? Шасси с Оракл DB заехало в прод в 2016м с 24 дисками по 146. В 2021м в нем ушел один диск.
По runbook прямо предписано ставить на замену то что есть сейчас в наличии из SAS и ближайшего размера, а там и размер и производитель были другими.
На «зоопарке» из накопителей шанс, что массив будет регулярно падать в состояние degraded — в разы выше»
хех, так вы о разных зоопарках говорите.
зоопарк новых, регулярно заменяемых дисков, в условиях нормального ДЦ или серверной комнаты — одно дело, зоопарк б/у-шного, которое уже отработало по 5-6 лет (а то и более), да ещё и дома или в мелком офисе — совершенно другое.
Хотите пример? Шасси с Оракл DB заехало в прод в 2016м с 24 дисками по 146. В 2021м в нем ушел один диск. "
по-хорошему в 2021м надо было бы отправить на свалку все 24 диска и переехать на ssd.
Знаю, знаю порядки и бюрократию в энтерпрайзе, эти вещи иногда занимают годы даже при наличии финансирования.
Формально деком не объявили — ретрофит никто делать не стал.
По производительности — всё было в пределах ожидания, даже на шасси с v2 камушками.
Слышал, что рекомендуют для домашних рейдов ставить одинаковые диски, но из несколько разных партий. Например, купили диск, он сначала поработал в одиночку, затем докупили такой же, сделали рейд 1.
ТС, не объявляйте хотспэр. Хотите — держите, но не объявляйте, чтобы не было авторебилда.
маленький, скромный массив.
Под нагрузкой — легко
Страшней, когда ребилд 3+ суток
В первом случае действительно есть шанс, что в процессе ребилда навернется еще один диск, поэтому, я, когда оказался в такой же ситуации (с 1-м рейдом) сначала делал бекап самых важных данных, потом менее важных (насколько было место), а потом только ребилдил массив.
С 6-м же рейдом можно смело менять диск и наблюдать за ребилдом — если вдруг в процессе ребилда будет зафиксировано ухудшение состояния (или полный выход из строя) еще одного диска, процесс срочно прекращается и начинается бекап.
Если бы мне сейчас пришлось строить рейд из нескольких новых дисков, я бы выбрал 5-й, как более эффективный по используемому месту. Если бы из нескольких б/у — то 6-й, чтобы подстраховаться. Но это лишь мое мнение :)
P.S. На одной из работ был 6-й рейд на 8-ми дисках, который каждую ночь бекапился на другой точно такой же рейд. Надежно? Вроде очень. Что же вы думаете — данные все равно однажды потеряли по причине выхода HDD из строя :) Но там человеческий фактор оказался решающим.
В двух словах: когда в рейде стали выходить из строя диски, админ обнаружил, что если их менять местами с запасным рейдом, система продолжает работать. Таким образом, он однажды вытащил третий диск из массива и тот развалился. Данные были зашифрованы трукриптом (или бесткриптом, не помню), в восстановлении отказали все известные столичные конторы.
" админ обнаружил, что если их менять местами с запасным рейдом, система продолжает работать"
уже на этом месте весело.
или «админ обнаружил», или вариантов нормально эксплуатировать массивы не было, нередко ж оно как происходит:
Raid, да, он нам нужен… давайте купим, нередко берётся дорогая модель, а потом хлоп! денег на обслуживание нет, купленной поддержки (она нужна, чтобы вам быстро помогли решить проблему и/или быстро заменили) нет.
Тем не менее, считаю, что надо было при выходе первого диска из строя пойти к директору, а при выходе второго (это было с достаточной разницей, около месяца) просто выключить сервер.
Сервер бы сам выключился. Потом. Без него.
а если такой тип просто один из клиентов — главное вовремя письменно предупредить, касается работы с клиентами от мелкой конторки до крупного энтерпрайза, вся разница в форме ( и адресате) написания письма.
потом, когда случается ой-караул, «а мы предупреждали».
Таких дерьмекторов как мух.
типичная ошибка домашнего рэйдостроителя: рассуждать о надёжности логики массива, забыв про то, в каких реальных условиях тот массив работает.
Какой-то комп, или небольшой NAS, UPS чаще всего нету, и тут Вася делает ухх, raid-массив, это же круто и надёжно.
Многие бытовые NAS, кроме всего прочего, даже с 7200ми дисками не очень дружат, если заполнить все слоты, перегрев и вибрации, плюс маломощные БП, знаю случай, когда банально не хватало тока.
Тут вероятность сбоя и 5-го, и 6-го массива примерно одинакова. Но автор не планирует эксплуатировать под серьезной нагрузкой, так что вряд ли для него это важно.
Не очень понятно, что именно вы хотели сказать, можете подробней описать?
P.S. Про отложенный старт я и писал.
Ёмкость у них (в случае массива из четырех дисков) одинаковая, да.
Но шестерка сохраняет работоспособность при отказе двух любых дисков в массиве. А вот 1+0 только если эти диски принадлежали к разным зеркалам. В случае отказа двух дисков, зеркалировавшихся друг на друга, вы по сути получаете raid 0 с отказавшим одним диском. Т.е. проще говоря — потерю всех данных
А с точки зрения надежности 10-й рейд проигрывает 6-му.
То есть, с точки зрения функций рейда, основная характеристика — отказоустойчивость. С точки зрения пользователя, основная характеристика — надежность. При этом, они связаны и, по сути, в данном контексте вполне понятно, о чем идет речь. Так что не стоит придираться :)
И тут достаточно четко понятно, что я говорю про надежность. Да и автор как бы вторым предложением обзора поясняет, для чего ему рейд:
И ниже:
Я вообще не понимаю, откуда взялась речь о производительности? Коммент mitiok был, как бы, не в тему, но ему там объяснили, я повторять не стал.
Речь не об экономии дисков, а о том, что raid6 гарантированно отказоустойчивоств при выходе из строя двух дисков массива. А raid 10 — одного. бОльшие количества возможны, но не гарантированы.
При любом количестве дисков в массиве количестве дисков в массиве.
К тому что при этом raid6 при количестве дисков >4 даёт выигрыш а полезной ёмкости можете относится как к приятному бонусу
Хотя если ещё подумать, то оба эти варианта для «бедных», раз есть RAID 60.
Ещё раз: при любых раскладах raid6 обеспечивает бОльшую отказоустойчивость, чем 10.
При качественном контроллере обеспечивая ту же производительность (ну и выигрыш в ёмкости при количестве дисков >4)
А raid10 будет выдавать х2 на запись и х4 на чтение.
Никаких теоретических препятствий иметь производительность x(N-2) на запись и даже xN на чтение (при чтенинии нескольких блоков) у raid6 нет.
Что прекрасно демонстрирует zfsный raidz2 на более-менее жирном железе.
Но многие low-end контроллеры (и high-end былых лет) типа умеющие в raid5/6 по факту демонстрируют по современным меркам удручающую производительность. Но это проблема не технологии как таковой, а скорости вычисления контрольных сумм железом.
10-тка проще, не требует ресурсов на вычисление, но надёжность ее хоть и приемлемая, но слабее чем у 6-ого, это бюджетное решение для тех серверов где трубуется максимальная производительность, с минимальным уровнем надёжности, т.е по сути сильные стороны 1-ого рэйда усиленные нулем в плане скорости. Сколько дисков в такой массив не ставь (можно собрать много единичек и объединить их в ноль), всегда будет эффективная ёмкость 50%, но чтение будет идти со всех дисков массива сразу, за минусом разности задержек между дисками, а вот запись уже пойдет по сути на все диски так же, но максимальная теоретическая скорость упадет в два раза
В шестёрке надёжность выше, и эффективность то же, но раскроется она на большом кол-ве дисков. Если смотреть массив из 4-х дисков, то 10тка эффективнее во всем, но менее надёжна. Но под 6рку сложно собрать быстрый на чтение массив(из-за сложности найти быстрый контроллер, не 100% дисков участвуют в чтении там), у него другая изначально задача.
есть кстати ещё тот же 60 рэйд, и 1e raid.
ЗЫ: даже не так выразился, я то согласен за 10-й, но не всегда 4 диска — это не всего обязательно 10.
Там ведь простой XOR, ЕМНИП.
потолок 2.5" 10k — 2.4тера, им уже лет 5 и ничего нового на этом поприще больше не будет.
Могу ошибаться, но, кажется, самые первые 15К были с дисками побольше размером.
как уже выше написали, новых нет уже много лет, кроме спец. поставок для старых корп. заказчиков и их legacy. И это дорогущие диски смешного размера.
Так что купить вы сможете только сильно б/у — шные диски, которым 5-7 и более лет. Впрочем, они зато будут дешёвыми.
Учтите, когда в таком массиве вылетает 1й диск, начинается ребилд, те. повышенная нагрузка на все остальные диски, в результате они нередко начинают сбоить в процессе ребилда.
У контроллера же логика простая: сбой ->> вылет диска, а тк. 1 уже вылетел, то это развал массива. И добро пожаловать на восстановление R5, процедура весьма недешёвая.
Проблемы и минусы есть, плюсов не видно.
Даже в теории — менее надежно, чем новый диск из магазина.
Так, для погуглить: посмотрите кривую отказа дисков после 60-го месяца работы в идеальных условиях серверного помещения.
Про домашний старт-стоп, калечный блок питания и отвратительно охлаждение для более горячих энтерпрайз-дисков — тоже можно погуглить/посчитать.
ну и окончательное решение по накопителям я ещё пока не принял.
Так же выводы и оценка последствий для тех или иных наборов оборудования, к моему глубокому сожалению, аналогичные.
Жаль.
дёшево, объёмно, в теории надёжней чем одиночный диск из магазина. "
Вы бы, для начала, подучили теорию. А потом посчитали затраты и гемор.
не обижайтесь.
И тут явно нет понимания, что нет смысла дома в сверхнадёжных дисках, если вся важная инфа не в нескольких копиях, потому что например провод 220 коснулся радиатора в БП — и минус вся начинка. Из реального опыта. И не важно, был там 1 вд грин или 10 сас — все выгорят при 220 на входе.
ЗЫ любой диск может отказать на пустом месте, хдд и ссд, новые и старые, бытовые и серверные… Есть пик первые пару месяцев на заводской брак — и потом они все примерно одинаковые в отказе, пара процентов. При этом у меня есть десяток дисков с наработкой около 15 лет, это они не просто лежали, а работали.
… и бесплатной серверной комнате с охлаждением, резервным питанием и звукоизоляцией.
там, где они обычно стоят, в ДЦ, это не проблема.
А ежели кто себе домой берут, или в офисные компы, так они сами себе злобные Буратины.
В сервер — более спорно, но есть многолетний опыт с samsung pro серией под БД — износ там до сих пор процентов 30, примерно по 10% в год.
Дома ещё круче, ссд кингстон на 120 гиг под СВОП — лет 5 уже, и помирать не собирается.
Кеш записи без резервирования (батарейка/ионистор) — слабоумие и отвага :)
1. WB можно включить как для самого контроллера так и для накопителей
2. Доступность этой функции (принудительного включения WB) зависит от фирмвари контроллера
3. У Вас проприетарная модификация от NEC, а не 9267 — часть функций могут не работать или работать иначе, даже через CLI
вы изначально написали что включить можно, я привел при ее что нет, и это по сути верно с точки зрения безопасности и прибыли для производителя).
Я Вам говорю «в рамках» работы в том числе с контроллерами LSI 15+ лет, что Ваш «опыт 1 экземпляра», который Вы пытаетесь глобально эстраполировать, не является репрезентативной выборкой.
И куча «тезисов», выдвинутых в обзоре, притянуты за уши ввиду околонулевого опыта.
Причины моей уверенности, что Вы нуб в серверном и рейдах — непонимание, что
«LSI 9267-8i» и «N8103-150» не являются близнецами.
Пассаж про «с точки зрения безопасности и прибыли для производителя» — это из области заговора рептилоидов.
лучше сделать програмный рейд 1 из двух бу дисков на пару терабайт
скорость будет примерно таже, зато не будет проблем, если сдохнет сам контроллер (придется искать такой же)
цена тоже примерно таже
жрать и греться будет меньше
«не будет проблем, если сдохнет сам контроллер (придется искать такой же)
цена тоже примерно таже
жрать и греться будет меньше»
То есть, работаете вы на чем угодно, например, на ссд, чтобы было быстро. Далее настраиваете периодический бэкап на внешнее сетевое хранилище, где уже рейд.
Рейд, начиная с 1 уровня — это уже поиграть в отказоустойчивость за счет избыточности. Это когда выход одного (нескольких, смотря от решения) носителей не поломает консистентное состояние дискового пространства, т.е. нашего массива. А уже что лежит поверх этого массива, какая файловая система, какие файлы и так далее — эти задачи рейд не решает.
Опять же, не обязательно. Я могу работать на raid1, чтобы если вдруг чего — поменял винт и работаешь дальше. И тут же делать резервную копию на одинокий внешний hdd, если дропнул файл — полез в бекап, достал копию.
Рейд и бекапы — это разные технологии, они просто часто идут рядышком. Но они не взаимозаменяемы.
Если бэкап будет основан на ручных действиях (подключить диск, флешку, вставить DVD-RW и т.д.), рано или поздно дома на это забьют. Так не будет работать, бэкап должен быть строго автоматический, даже без единого запуска программы или нажатия мышкой со стороны пользователя.
И что имеем в остатке? Удаленный облачный сервис или «локальный облачный сервис» — то есть, сетевое хранилище :) Можно бэкапить на второй жесткий диск, но это тоже менее надежно — если, например, компьютер сгорит из-за повреждения БП, бэкап тоже потеряется.
В итоге, получается, бэкапить надо на другое устройство. Но оно должно само быть достаточно надежным, чтобы в случае чего этот бэкап оттуда можно было успешно извлечь. И тут уже на сцену выходит рейд.
А я о чем говорю? :) Просто изначально опустил всю долгую цепочку размышлений и сразу написал итог, например, к которому пришел сам — когда сохранность данных имеет значение, стоимость лишнего жесткого диска уходит на второй план, и «жаба» молча смотрит со стороны.
Ну, в общем, да, но не совсем. Ваш пример, когда работают прямо на рейде, это уже какая-никакая, но замена бэкапам. От кучи разных проблем не спасет, но если цель именно защититься от отказа жесткого диска — прокатит. Я так делал, кстати, много лет.
Никакая, и не замена.
Вот именно поэтому это и называют отказоустойчивостью.
нет. Совсем не замена.
" но если цель именно защититься от отказа жесткого диска — прокатит. "
только и исключительно в одном из типов причин отказа диска, а вариантов причин отказа — много.
Питание у дисков в массиве общее, логика записи общая, если снаружи пришли вибрации — они тоже общие.
И всё, приехали.
Тем не менее большое спасибо за информацию!
Для начало теорию почитаю, а потом вопросы.
По опыту, достаточно неплохое кли у адаптеков.
Про WebBIOS я бы конечно сказал но боюсь что меня забанят пожизненно за такое количество нецензурных слов.
Вот прямо таки DVD на 100 гигабайт?
Кстати, mdisc в России я тоже в широкой продаже не встречал, искал некоторое время назад.
Если сдохнет привод то возьму опять, они дешевые около 50 долларов.
Да на 100GB беру на таобао
Может неправильно выразился что это ДВД это ДВД Блю Рей
И насчет магнитооптики тоже все достаточно дешевое, привод около 50 долларов, а носители по 20
Блюрэй — это не ДВД. ;)
Сколько такая пачка стоит?
к повреждениям у них такое же отношение как и у dvd? т.е. в случае чего прочитать получится через спец утилиту, которая обойдет повреженную область?
Поэтому я и использую еще и другие типы носителей такие как магнитооптические диски и картриджи rav iomega. Надеюсь что на каком нибуть из трех типов носителей информация сохранится как надо и надолго.
Для холодных бекапов данный способ ещё норм, но если вы хотя бы раз в месяц обращаетесь к этим данным, уже не очень выходит…
Я так понимаю вы ему скармливаете диски не на 35ГБ, а на 1,3ГБ?
У меня есть МагнитоОптический привод FUJITSU MCM3130AP вот ему я скармливаю диски МО 1.3 GB
Не забывайте, что кроме дисков могут дохнуть и контроллеры. Хотя это реже бывает, у меня за 10 лет в массиве RAID10 вылетело 2 SAS-диска, а контроллер пашет без проблем.
Заманчиво, но вот бэушность вкупе с тем, что оно поедет почтой и может где-то стукнуться, меня бы отвратили от подобной покупки. Предпочёл бы заплатить дороже, но взять новый диск в оффлайновом магазине с гарантией. Впрочем, пятёрка, купленная в CU у меня до сих пор нормально пашет, а десяток дисков, купленных в оффлайне одновременно, вылетал за пару лет почти полностью (уронили их там на складе, что ли). Но всё равно, доверия к магазинным дискам у меня больше, чем к купленным в интернетах, да ещё с большим пробегом.
Ну и какой бы вариант в итоге не выбрали, не забывайте, что RAID'ы — RAID'ами, но заменой бэкапу они не являются.
Лично у меня подобный контроллер просто в режиме HBA работает, а массивы я уже программно создаю.
конечно raid это не понацея, как и хранение их например на надёжном SSD за несколько сот баксов, важные файлы надо держать в разных надёжных местах.
Но у меня достаточно было примеров, когда диски с сервера снимал и переставлял на десктопные задачи — и после этого они довольно быстро помирали.
В серверах отработали ещё 3-4 года. Один вроде ещё жив, но просто лежит на полке как архив.
Seagate Constellation могу вспомнить ещё, две трёшки. Отпахали в зеркале шесть лет, после разбора зеркала один капитально посыпался в течение года.
Из интересных неубиваемых были Constellation 1TB, было очень много и в десктопах и в серверах.
б/у диски да, лотерея. Желаю что в том году была возможность купить парочку новых дисков на 2 Тб по скидке, а я ее купил… Пусть там черерпичка была, но в целом, мне хватило бы, но с другой строны, жизнь же продолжается, что-нибудь другое глядишь подвернётся интересное.
Другое дело — винда10 и дальше уже на простых винтах хреново работает, ссд ей подавай практически обязательно.
Но так то да, правильное применение черепицы — избегать больших объёмов записи за раз. А это значит — в рейдах использовать противопоказано. Идеально — записал один раз, а дальше только читаешь.
Я их под медиатеку и архивы использую — фильмы, музыка, дистрибутивы и т.п.
Но торренты на системном диске и с cmr будут мешать жить.
Лично я качаю на ссд, потом скидываю на черепицу.
Но я свои черепичные диски брал в USB-коробках процентов на 30-40 дешевле, чем аналогичные диски в рознице. Потому вполне готов был смириться.
В России сегодня, впрочем, подобное маловероятно.
А вот на каком-нибудь амазоне или бестбае — запрость.
Впрочем, там доставка всю экономию съест.
Шокером в сата линию.
К счастью, на полу был линолиум и диск выжил. Вернее, потом все же вышел из строя, но чуть позже аналогичного диска, купленного без эксцессов :) Да и 500 ГБ у сигейта были проблемными…
Согласен. Свои домашние диски стараюсь не выключать. Раньше компьютер круглосуточно работал, сейчас перенес их в сетевое хранилище.
увы, теперь они все нежные, что черепичные, что нормальные с PMR.
Сильно зависит от того, как удар придётся. Плюс он далеко не один может быть в пути.
P.S. пару месяцев назад решил поиграть в лотерею и заказать диск на Али. Пришел вроде оригинал, линейное чтение по всей поверхности прошло без проблем. Остальное поведение диска (нагрев, вибрации) от других не отличается. Правда, диск пока не эксплуатируется, лежит в столе.
Я и пытаюсь сказать — да, могут стукнуть. И в теории может прийти кирпич. Но есть много случаев, когда все доходит почтой нормально. Это, опять-таки, лотерея в какой-то степени. Если цена интересная, попробовать можно.
Бывало что приходили 3.5 винты в обычном бумажном почтовом конверте, где единственная защита — это пупырка внутри конверта — но пока работают, жалоб не замечено.
Но при покупке бэушного винта на таобао и отправке его почтой шансы «выиграть» проблемы, думаю, повыше будут.
Поинтересуйтесь у ближайшего дистрибьютора винчестеров, сколько винчестеров возвращается именно по причине удара.
А так же процент брака еще при комплектации заказа у мелко-средне-розничного реселлера, когда накопители идут в металлизировоанной упаковке. При том что накопитель в лучшем случае роняется с высоты 20-30 см на упаковочный стол.
а так, если приложить серверный винт пару раз — можно скончаться от носового кровотечения :D
Может подскажете самую производительную и менее греющуюся SAS карту?
а вообще, контроллер должен вести массив самостоятельно, смотреть смарт дело не плохое, но особо не нужное, достаточно иметь резервный диск замены, и контроллер уже сам все сделает, после того как один из дисков по какому то признаку будет выкинут из массива. только если в случае ssd смотреть объем записи, тогда smart пригодится да.
Предприятие организовывает ежегодный медосмотр своих сотрудников, по результатам — профилактика, предупреждение профзаболеваний, и т.д. Человек проходит медосмотр, но через день ломает руку и уходит на больничный. Мораль?
Тоже самое и с hdd. В большинстве случаев, при правильной эксплуатации (вибрации/электропитание/температура и т.д.) износ винта прогнозируем. Т.е. его можно своевременно заменить еще до того, когда он выйдет из строя (в отличие от ssd, где вероятность спонтанной поломки в разы выше).
Диск еще исправен, читается, но сектора уже начали расти. Вот тут-то мы диск и заменяем, не дожидаясь, когда он вылетит в субботу ночью.
Вы сейчас воюете с ветряными мельницами.
Есть LSI 9264-8i — в базе не знает RAID5 и SSD кеш, есть ключ, который только Р5-6 добавляет, на аил купил ключ для кэша как в лоте написано, но его не распознает мой контроллер — хочется кэша, в сервачке 8 дисков для ESXi.
Софтовые ключи, что открыто есть в инете не подходят, да и на 30 дней включать нет смысла.
Кстати, а там разве все ноды с Xen?
Там и линь их собственный, от редшапки одолженный.
По поводу ESXi — почти весь enterprise на нём сидит, возьмите любую крупную компанию и там будет пачка кластеров ESXi.
Есть ещё OpenStack, но его мало кто осилил.
Есть ещё Proxmox и он неплох, когда в парке 30-50 серверов, но даже 200 серверов в проксмоксе это уже как минимум неуютно, а когда речь идёт о тысячах — остаётся либо ESXi с его VSphere и VCenter, либо что-то своё (но такое себе могут позволить только монстры типа Яндекса).
Вряд ли янедкс и прочие чисто свое делают, скорее, патчат опенсорс под свои нужды.
У OpenStack'а есть 2 штатных хранилища:
Cinder — не то, чтобы мертворождённый, но малоизвестный проект со своими заморочками, который особо нигде и не встречается и найти под него специалистов крайне сложно (и не факт, что нужно)
CEPH — штука всем великолепна, на её базе можно строить отличные S3 хранилки, но как хранилка образов это так себе вариант. Для блочного устройства выдаёт средненький результат на SSD (но учитываем стандартный replica factor = 3 и плачем) с сильно проседающими IOPS'ами, выдаёт совсем грустный результат на HDD.
А ещё у OpenStack'а по умолчанию «из коробки» есть дофига не сильно нужных, хоть и полезных сервисов — типа собственных DNS, bare metal provisioning, управление сетями (не помню как зовётся) и так далее и тому подобное.
В общем, такой «швейцарский нож», который может буквально всё, но немного криво и чуть-чуть косо.
Конечно же к OpenStack всегда можно подключить enterprise хранилки по SAN или по iSCSI, но раз уж везде Enterprise, то зачем тогда тут этот OpenSource? :)
Не спорю, тот же Яндекс для своих облаков использует либо голый KVM с обвязкой, либо очень сильно переделанную приватную версию OpenStack'а.
Публичной версии хорошо работающего для большинства задач OpenStack'а… банально не существует.
Но тут и кроется засада — подобные вещи себе могут позволить очень крупные IT компании, которые готовы содержать отделы разработки и поддержки. Когда у тебя несколько тысяч серверов с планами расширения до десятков тысяч — команда в 50+ человек чисто на развитие и поддержку «compute cloud» выглядит вполне нормально.
Если же серверов несколько десятков, возможно сотня — ESXi становится экономически выгоднее (не говоря уже про то, что лицензию на ESXi вполне можно найти на торрентах или у знакомых и тогда «стоимость» ESXi будет ещё ниже).
p.s. И дело не в «devOps» — в двух немаленьких компаниях около года искали хороших специалистов по OpenStack'у и готовы были даже неразумные деньги платить,… но не нашли. Таких специалистов физически почти нет на рынке. Есть масса людей, которые «ну мы поднимали, настраивали и у нас работало», но нет тех, кто очень глубоко разбирается. Скорее всего они есть, но их единицы на всю страну и их и так неплохо кормят на своих местах.
У яндекса есть платная сажировка, сами готовят специалистов. У озона в эти выходные идет контест для го программистов. Т.е. такие компании понимают что кадры надо самим готовить.
Если же серверов несколько десятков, возможно сотня — ESXi становится экономически выгоднее (не говоря уже про то, что лицензию на ESXi вполне можно найти на торрентах или у знакомых и тогда «стоимость» ESXi будет ещё ниже)."
Нередко даже выгоднее «бесплатного» Proxmox, особенно когда у работников европейские заплаты, и экономия на лицензиях не сильно существенна.
А вот стоимость человеко-часов — огого.
Ну и за полную версию xen orchestra, без которой, впрочем, можно прекрасно жить.
Как говорят наши виндузятники — виртуализировать винду нужно именно на Hyper-V, из-за особенностей лицензирования выходит сильно дешевле.
Линукс на ферме Hyper-V они даже в страшном сне видеть не хотят.
Винда на ESXi хороша только в случае бесплатных (читай — пиратских) лицензий.
Но если VM с Windows запущена внутри Hyper-V, то в этом случае лицензии берутся с самого Hyper-V и нет необходимости их отдельно докупать.
В итоге винда на Hyper-V обходилась существенно дешевле, чем на ESXi (бесплатную виртуализацию там не рассматривали).
Ну или кто-то кого-то не правильно понял.
Плюс никто не мешает им рулить с десктопной винды, которая стоит заметно дешевле серверной. Или вообще уже у вас в наличии имеется.
А у китайцев, кстати, зачастую можно и проф поставить было. Я на тексластовский ноут ставил — и оно автоматом активировалось.
Например, если запустить вот эту штучку в режиме «HWID», то винда будет навечно активирована цифровой лицензией. При этом активация на серверах MS привяжется к профилю железа и после любой переустановки начисто уже без всяких активаторов система будет получать статус «активирована» при первом выходе в сеть.
Именно так активированы все эти китайские ноуты с алика на которых активация сохраняется после переустановки системы.
Но это не делает такую винду лицензионной, что неприемлемо для случаев, когда требуется лицензионная чистота. А если она не требуется, то на любой пк/ноут можно накатить проф с любым активатором, какой душе угоден, да хоть vlmcsd в локалке поднять.
Рулить можно из клиентской форточки, стоимость которой на порядок, а то и два меньше лицензии сервера. Административные тулзы ставятся отдельно.
Либо, при использовании гипервизора, можете запустить две копии этой винды в виртуалках.
Какой гипервизор при этом используется — без разницы. У меня стоит esxi — потому что есть требование пробрасывать usb-ключи внутрь. hyperv этого не умеет.
а купил такой
где-то читал, что их можно перешить
второй 17В выдает
>RAID5
>аппаратными средствами
> б/у серверных дисков
Ржу.
P.S: диски брал по 6 баксов за 100гб, 14 за 200. Вообще, если есть способ доставить, с ебея американского очень выгодно брать можно, ссд сас часто вообще дешевые.
Контроллер должен видеть как sas так и sata накопители. Скриншоты бы как там все это у вас выглядит, а то я не особо понял о чем речь. попробуйте тот же MSM поставить, там все наглядно, если ещё не установлен у вас.
с san не сталкивался, мб там что то зашито на уровне совместимости только с валидированными накопителями, из листа совместимости, но утверждать не берусь.
Если IR — то за Вас никто не будет инициализировать диски и собрать RAID/JBOD, соотвественно, в ОС контроллер ничего не покажет
Штука еще в том, что когда подключены диски на разъемы, не дает зайти в фирмварь контроллера при загрузке
Если Вы не перепрошивали 1068 — там 100% IR-прошивка, соответсвенно, оно изображает недорейд и предполагает предварительную инициализацию и сборку тома/массива
Собственно, сам факт, что Вы можете зайти в БИОС S20 — это признак, что IR-фирмварь :)
IT — это «чистый» HBA, у него нет никакой морды/настроек
В серверном варианте, если Вы не придерживаетесь HCL — Вам никто ничего не должен :)
Перешивайте на IT — теоретичски все будет ОК
не забудьте скопировать номер SAS до попытки прошить и забэкапить текущую прошивку
решил — толи временным вытаскиванием 10Гб сетевухи, толи перестановкой их местами.
и 4мя оставшимися портами — наружу
На тот момент — практически топовый 8-канальный SAS SOC, с базовым мозгом и 64к «памяти» для 0/1/10. Учитывая глубокую очередь (256 команд), переупорядочивание команд и 2 пути данных — великолепнейшее универсальное решение для начального энтерпрайза того времени
При том, что купленный там же на ebay год назад LSI 9260-8i (SAS2108 — M5015) отлично работает на домашнем, не выключаемом ПК.
Кстати проверьте термопасту на чипе — она как камень. Заменял её.
Вот чем отличается unraid, xpenology и debian в плане работы с файловой системой? Правильно, ничем. Под капотом вся та же ext4 и mdadm — т.е. берем винты с рейда и работаем с ними в родных линуксовых тузлах.
Я же говорю, это вопрос религиозных войн. Помните анекдот
Тут тоже самое. Кому что ближе. Я вот аргументированно скажу, что синолоджи для дома лучше unraid, потому что существует проект xpenology. Для, я знаю что они не продают свою ось вне своего железа, но тем не менее: 1) она доступней в плане вареза, сейчас уже 5/6/7 версия (формально там загрузчик и совершенно оригинальная ось, есть нюансы по активации каких-то фитч, но не вникал) 2) она гораздо доступней в плане комьюнити, в том числе, русскоязычного 3) изкоробочный функционал закрывает большинство домашних кейсов, для остального туда завезли докер. Но тут веское слово скажет предполагаемое железо и самое главное — выполняемые задачи.
btrfs из коробки используется для дисков кэша записи. Хотя и там тоже можно xfs поставить, к примеру.
А на счёт траблшутинга — я как раз благодаря btrfs поймал сбойную память. Она жаловалась на несовпадение контрольных сумм и переходила в RO. Я сперва грешил на саму фс — память у меня до этого год без проблем на десктопе работала — но в итоге таки проверил её и выяснил, что один модуль сбойный.
unraid удобное решение для дома, если не хочется странного. Впрочем, если хочется странного, то там можно и zfs прикрутить, только это ручной работы потребует.
Во затейники, знатно извратились.
Вы, мягко говоря, заблуждаетесь.
Восстановление данных с поломанных массивов и дисков с ext3/4 & xfs — непростая и далеко не всегда успешная процедура.
В случае raid тем более, сложно и недёшево.
Рассказываю один раз, для тех кто никогад не пробовал.
Если вам нужно скопировать данные с unraid массива просто вытаскиваете один диск, подключаете его к SATA контроллеру и копируете. Вот такая вот нетривиальная задача.
У unraid есть как плюсы, так и минусы. Но для дома, на мой взгляд, это одно из самых удобных в использовании решений — небольшие накладные расходы, но при этом повышенная надёжность. Впрочем, бэкапы всё равно делать надо.
Во взрослом суровом мире нет проблем взять программный массив и (пере)собрать его на другом железе, разве что да, нужно таскать все два-три (или сколько там) уцелевших винта — ну, это расплата за избыточность. Ну или например, загрузиться с livecd и подчинить систему.
Каша же будет после аппаратных рейдов. Там уже либо искать контроллер (в идеале просто достать его с зипа) либо искать спец-софт и нужно уметь в него.
1) Можно было в массиве использовать диски разного размера
2) Можно было спокойно менять, добавлять и удалять диски из массива без полной его пересборки
3) Чтобы в случае гибели двух (трёх — если у вас два парити) винтов на остальных данные оставались живы, а не превращались в кашу.
Конечно, есть и недостатки, но лично для меня они перевешиваются вышеперечисленными достоинствами.
Если у вас в raid5 вылетело два диска, то на остальных дисках у вас будет каша. Если в unraid вылетело два диска, то на остальных дисках будут нормально читаемые файлы.
Профи перед тем, как делать raid, думают головой.
В том числе и про то, что raid никогда не был, да и не будет заменой бэкапам.
во-во.
что проблем починить Raid и скопировать данные, если они ещё живы, у нормальных профи нету.
А заводить Raid тем, для кого это сложно, обычно просто нет смысла.
— А от всего остального, начиная от аппаратных сбоев, затрагивающих весь массив, и продолжая логическими сбоями при записи, Unraid не спасает точно так же, как и обычный Raid.
Только не надо «а вот я получил смарт». Можно. Но с приседаниями. И диск будет не /deb/sda, а например для lsi
А надо так
Логично и удобно, не правда ли?
BBU приехал с дохлой банкой, количество разрядных циклов около 3500…
поменял литиевую банку, вычитал дамп программатором, использовал прогу BatDumpEditor для правки дампа. зашил обратно. Profit.
когда то это был очень популярный контроллер). там как раз lsi2108 и 512 мб кэша. Даже на экспандеры из активно вешали.
В 2022 году я бы категорически никому и ни при каких обстоятельствах не рекомендовал бы использовать аппаратный RAID, тем более древний и из неизвестного источника.
Современные системы держаться на столпах reliability-observability-performance — надежность-наблюдаемость-производительность.
Надёжность системы, построенной на бу компонентах неизвестной степени запилености, на мой вкус, где-то в районе нуля, сколько спар не поставь. Проверить статус бу SAS дисков весьма нетривиальная задача (не верите — поставьте smartmontools и сравните вывод на SAS и SATA дисках, будете сильно удивлены). Диски SAS легко могли работать под какой-нибудь простенькой, но нетривиальной базёнкой, типа Oracle или мускул, запиливая в ноль не весь диск, а лишь его определённую область мелким блоком (так карта легла, REDO/FRA область, бывает, штош). Проверить статус контроллера — тем более, задача в домашних условиях не решаемая (на серверах fujitsu rx600 у подобных контроллеров массово от перегрева отваливались радиаторы, лопались от температуры пластиковые держатели радиатора, выводы делайте сами, что там происходит под BGA-корпусом, в некоторых случаях аж маска с платы облазила). Плавно переходим к наблюдаемости.
Наблюдаемость (не мониторинг в общем смысле, я разделяю эти понятия) — способность определить те или иные проблемы или проблемные места, или заранее, или же вот сейчас и здесь. Кратко — на LSI этот функционал стремится примерно к нулю (как, впрочем на любом avago/microsemi) — он НЕ нужен пользователю, с точки зрения производителя. Patrol Read — по сути игрушечная штука, которая иногда проактивно позволяет выявить 'отстающий' диск, вывести его, ни о какой сквозной целостности данных речи не идёт, а домашних условиях долговременного хранения данных без механизма контроля целостности ваши данные молчаливо и неотвратимо (см пунки надёжность) превращаются в хлам в самый неожиданный момент.
Производительность — не могу и не буду комментировать, просто тестировать fio или иной утилиткой ту или иную СХД-контроллер в отрыве от задачи — задача чисто для красивого скриншота, не более, я не вижу никакого смысла в 900 мб на чтение 4к блоком с пары-тройки дисков, которые с интерфейса физически больше 200-250 мб на внешней дорожке дать не могут, что там нарисовано — я не в курсе :) Пропускная способность — попугай, если не привязываться к IOPS и задаче. RAID6 на 4-х дисках даже комментировать бессмысленно (каждая 2 запись на медленный диск — это чётность, на этом всё с производительностью и подобной к-цией).
Мораль? Найти IT-фирмварь, избавиться от IR-микрокода (перешить или переключить контроллер), превратить его в тупой JBOD/SBOD, создать два диска под виндой RAID1, запастись дисками такого же или большего объёма — получить хотя бы подобие наблюдаемости и надёжности. Хочется большего — копать в сторону openzfs, с отдельно стоящим NAS, со сквозным скрабом.
Можно и подискутировать :)
Серьёзно, для условно-холодного хранения SAS HBA не самый лучший выбор, с другой стороны, нужно понимать риски и ограничения всех решений (я понимаю, что выделенный сервер хранения, да ещё и на липуксе, фряхе или производных с рюшечками аля unraid — не всегда вменяемый кейс для дома по массе вполне очевидных причин), чтобы осознанно делать выбор в пользу того или иного решения. Повторюсь — в случае домашнего применения SAS HBA неизвестного происхождения на SAS дисках аналогичного происхождения — плохой вариант, который потенциально может привести к проблемам, причины я вроде изложил.
mysku.club/blog/aliexpress/74477.html
mysku.club/blog/china-stores/55335.html
mysku.club/blog/china-stores/55275.html
для домашнего применения по-интересней будут (вроде на али 8-ми портовые тоже мелькают).
Глянул, с первого линка на контролере можно наколхозить выход со светодиодов на бекплейн )
Просто все это дело греться (а следовательно и кушать электричества) будет гораздо меньше. Не то, чтобы мне жалко электричества, нет; мне просто не нравится все это дело охлаждать/обдувать, раз уж речь идет о доме.
А в нашем случае, потенциально можно попробовать добраться до GPIO и программно поморгать светодиодом. Опять же, не смотрел, может энтузиасты уже что-то такое расковыряли.
Одинадцатый пин на разъеме питания, и запуск предотвращает, и светодиодом мигает :)
не соглашусь разве что с
" ilyxascrat
RAID6 на 4-х дисках даже комментировать бессмысленно (каждая 2 запись на медленный диск — это чётность, на этом всё с производительностью и подобной к-цией)."
В случае с ZFS некоторый смысл есть, конечно не с б/у-шными дисками и не с бу-шным sas контроллером.
производительность низкая? фиг с ней, для производительности есть ssd, а отдельно есть R6 массив, хотя, конечно, лучше тогда всё равно больше, чем 4.
нет смысла дома / в маленьком офисе, те. на малой нагрузке.
в nvme в данном варианте вообще нет смысла, sata ssd выше крыши.
трахайтесь потом с ними… узкая фича, для узких применений.
Спасает это от внезапных 10-100 сбойных секторов? да, скорее всего, спасёт.
Спасает это от внезапного вылета диска (1 или 2, или всего массива) по одной из десятков причин? нет, не спасает.
Спасает это от логического сбоя на уровне ОС или ПО и записи на диск мусора? нет, не спасает.
ну и толку?
Если есть желание разобраться — binwalk отлично «видит» в vdev наш gz (для того и сделал).
ну и zpool status -v test_pool позапускать, и не забыть сделать zpool destroy test_pool после всех тестов (если запустить scrub, ну или его zed вдруг запустит = перезагрузка, пул из саспенда вытащить нечем ;))
«раньше этот функционал использовал на переносных дисках, дважды был отличный сейв»
на переносных дисках zfs?
ну вы даёте, это ж нужно на всех концах иметь машины, его понимающие, плюс огромный износ флэша, если мы про флешки (а переносные диски с механикой уже много лет мало кто использует).
Насчёт флеша — фиг знает, не могу из практики ничего сказать, на больших сетах и ssd (не домашних) я не отмечаю катастрофы с дисками уже на приличной перспективе времени.
В общем-то, наличие ZFS лично для меня одна из определяющих причин, почему у меня винды нет (почти) нигде (вот, правда, сейчас пишу с ноутбука с вин10, я решил сохранить лицензию в нетронутом виде, это больше оргмера, нежели практическая).
" sata ssd выше крыши " для кэша.
На типовых скоростях, если не какой-то очень большой массив, нагрузка в виде сотен-тысяч клиентов и 10GbE (а то и вообще 40) линии,
sata ssd по скорости более чем достаточны.
При этом масса доступных новых серверных ssd, с огромным ресурсом, конденсаторами в питании и т.д., это если делать экономно.
В nvme — фиг вам, серверный вариант nvme это U2 диски.
> При этом масса доступных новых серверных ssd, с огромным ресурсом, конденсаторами в питании и т.д., это если делать экономно.
вот что-то на вскидку не удалось найти диски большой ёмкости (больше 6Тб) и DWPD = 3 и больше, буквально единицы и ценник конский.
и размер огого, и DWPD = 3, и чтоб недорого.
Это я себе сохранил, спасибо :)
> неправы адепты программного RAID, объяснять долго
Ещё c solstice disksuite/позже svm и vxfs/vxvm слушал разнообразные дискуссии 'почему аппаратный raid лучше', и вот тогда у аппаратных рейдов хватало козырей (было время, да), где-то с 2006-2009 года эта дискуссия утратила всякий смысл (лично для меня), с удовольствием послушаю мнение на современный лад (кроме шуток). С windows имею дело по касательной, но там тоже много новшеств за последние 5-7 лет.
Примеров практического использования SAS HBA RAID на современных системах и у меня хватает, большинство успешные, действительно работающие годами (было бы странно говорить другое — кто бы это покупал, если не было бы позитивного опыта). За редкими и очень мерзкими исключениями, которые портят всю картину — и молчаливая потеря данных, и тотальный развал — были прецеденты, когда и в резервной копии оказывались побитые данные.
Год назад в ZoL привезли draid (распределённый запасной диск), удаление диска из страйпа/raidz/draid, помимо сарафана изменений в менеджере памяти и прочих массы мелких 'ништяков' в виде zstd, поддержкой нативной криптографии — это сделало меня полностью щАстливым (ну почти) ;) Да, оно не для всего и не для всех, но дык кто-то дома блюстор умудряется развернуть и пользовать (всякие есть).
Справедливости ради отмечу, что с OpenZFS/ZoL тоже, простите, говна подъели, и весьма прилично — например, на крупных датасетах (десятки терабайт данных), например, теряли огромные порции инкрементальных снимков (нули получали, а не данные) при репликации. Короче, у меня историй много ;) И — да, я против такого рода контроллеров, особенно в домашних условиях и в означенных бюджетах ;)
Я как-то перезагружал сервер — увидел при старте, что контроллер жалуется на массив degraded.
Загрузился, полез в мегарейд. А оно пишет «массив degraded, но всё просто прекрасно, чего вы ко мне пристаёте?»
Обновил версию — она сразу письмами завалила про то, что «всё пропало, диск снимают, клиент уезжает».
Так что надо иногда всё же глазами смотреть, а слепо верить отсутствию писем не стоит.
я на днях заказал 4шт WD Red по 8Тб, так один с завода пришел дохлый — ёмкость 0Гб и в гарантии отказано — якобы физически поврежден. Хорошо, что магазин оперативно поменял диск и уже сам занялся возвратом моего.
Правильно ли я понял что их можно заменить обычными бытовыми SSD?
А для предотвращения проблем с Trim, можно выделять только 90% процентов на накопителе. Тогда SSD вроде хватает для нормальной работы хватает очисток проводимых контроллером самого накопителя.
Единственное возникает вопрос с живучестью SSD по сравнению с дисками при работе в RAID, особенно если он используется по базы данных.
ваш вариант это и корзину менять (если есть что) и докупать железо (а человек пишет про бытовые ссд, сразу западает мысль что денег ну совсем мало дают на обновки)
А ещё лучше SM серию, правда, их снимали с пр-ва.
www.broadcom.com/support/download-search?pg=Legacy+Products&pf=Legacy+RAID+Controllers&pn=MegaRAID+SAS+9267-8i&pa=&po=&dk=&pl=&l=false