Voice Home Assistant Preview Edition. Фирменная умная колонка на базе ESP32

- Цена: 5417 р.
- Перейти в магазин
Фирменная, опенсорсная(прошивка на базе ESPhome) умная колонка за авторством разработчиков Home assistant. О железке узнал совершенно случайно и не то чтобы я был фанатом голосового управления, но руки сразу зачесались купить и поиграть. Подробности под катом
В чём собственно прикол железки. Голосовое управление к HA прикрутили уже достаточно давно, можно с ним разговаривать через телефон, можно через смарт часы. Но вот именно «железной» колонки не было и не было доноров, которые можно было бы перепрошить(либо никто так и не заморочился). Народ городил различного рода самопалы, довольно популярным вариантом был модуль M5 Atom Echo, но работало это всё так себе. Ну и в отличие от — в этой колонке заявлен сдвоенный микрофон и качественный шумодав(забегая вперёд — действительно классно работает, на голову лучше альтернатив). Ну а ещё она стильная и с прикольным управлением. Цена за эту радость, впрочем, немалая. Как обычно, ничего нового.
Игрушка приходит в фирменной коробке из переработанного эко-картония.
 Внутри кроме самой колонки нет ничего интересного, только странная наклейка и стопка макулатуры
Внутри кроме самой колонки нет ничего интересного, только странная наклейка и стопка макулатуры
 Колонка питается через USB-C, имеет mini jack 3.5 выход на внешние динамики. Сбоку есть тумблер выключения, а снизу — отгибающийся кусок пластика, открывающий доступ к некоему Grove Port — куда можно подключать ряд датчиков платформы M5 Stack:
Колонка питается через USB-C, имеет mini jack 3.5 выход на внешние динамики. Сбоку есть тумблер выключения, а снизу — отгибающийся кусок пластика, открывающий доступ к некоему Grove Port — куда можно подключать ряд датчиков платформы M5 Stack:
 Колонка подключается очень просто. Включаем колонку(диодное кольцо на ней начинает мерцать бело-розовым), открываем на телефоне фирменное приложение HA, Настройки -> Устройства и службы. Вверху списка будет найденная по Bluetooth колонка с предложением её добавить.
Колонка подключается очень просто. Включаем колонку(диодное кольцо на ней начинает мерцать бело-розовым), открываем на телефоне фирменное приложение HA, Настройки -> Устройства и службы. Вверху списка будет найденная по Bluetooth колонка с предложением её добавить.
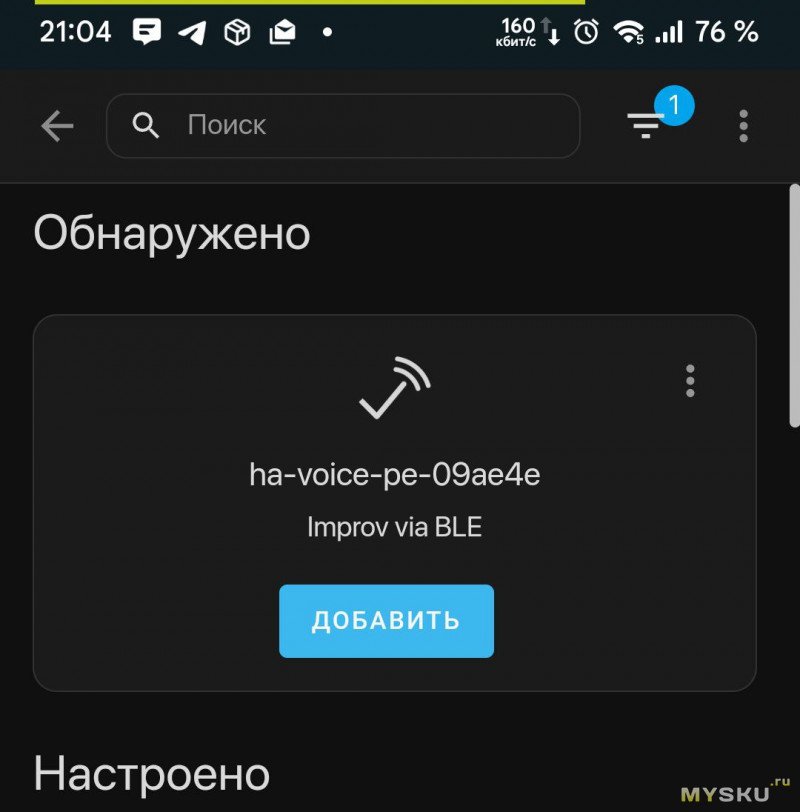 Жмём, вбиваем Wifi креды, колонка подключается, обновляет прошивку(если есть обновления) и предлагает её донастроить. В теории, дальше всё должно произойти также (next-next-next-готово), но у меня всё пошло немного не по плану и из вариантов мне был предложен только облачный сервис, что разумеется не наш путь.
Жмём, вбиваем Wifi креды, колонка подключается, обновляет прошивку(если есть обновления) и предлагает её донастроить. В теории, дальше всё должно произойти также (next-next-next-готово), но у меня всё пошло немного не по плану и из вариантов мне был предложен только облачный сервис, что разумеется не наш путь.
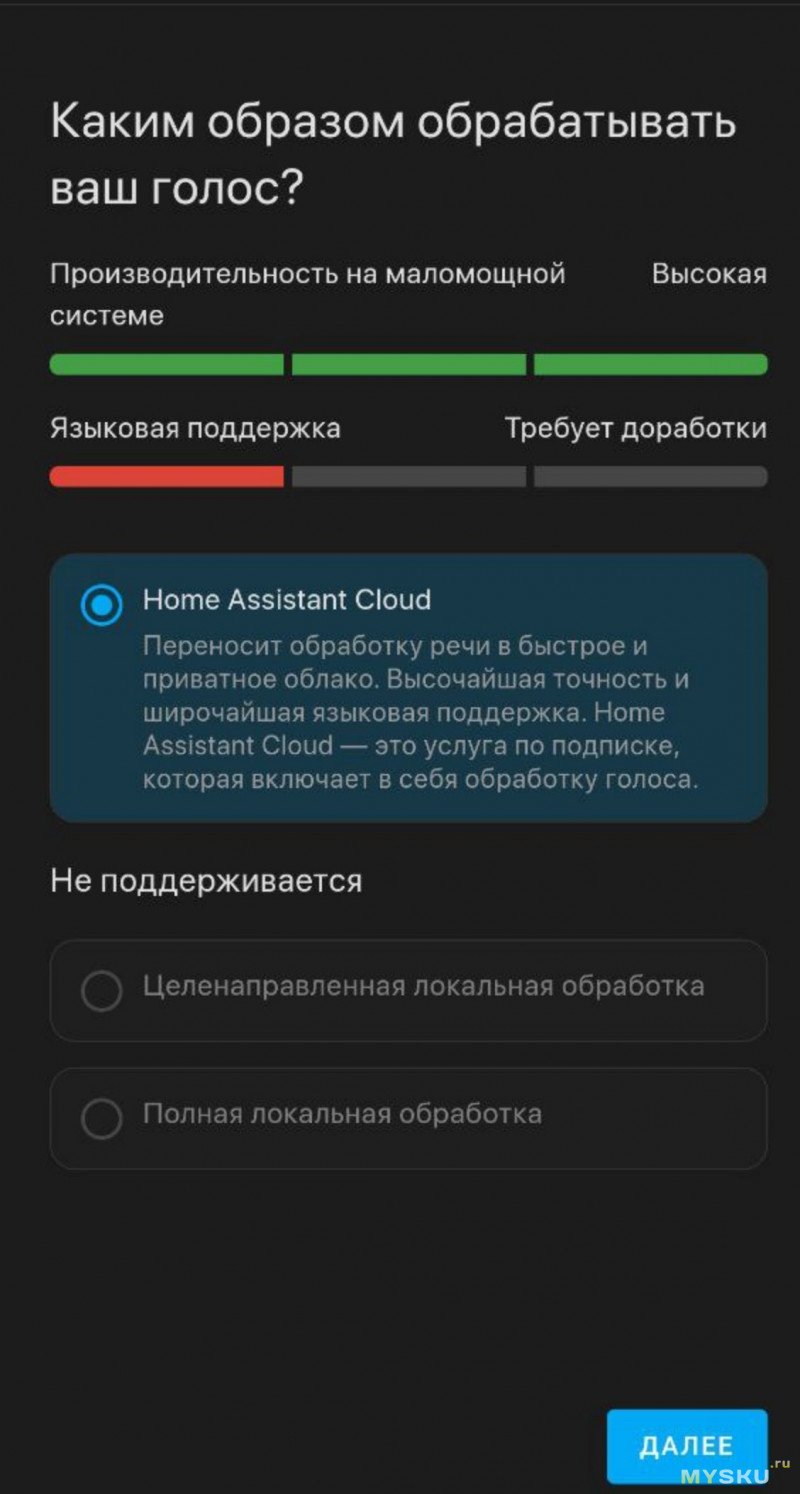 Подозреваю, связано с тем что у меня Core инсталляция HA, которая не поддерживает дополнения, в случае с установкой в виде докер образа либо через HA OS всё должно быть гораздо проще.
Подозреваю, связано с тем что у меня Core инсталляция HA, которая не поддерживает дополнения, в случае с установкой в виде докер образа либо через HA OS всё должно быть гораздо проще.
Так или иначе донастраиваем колонку с голосовым ассистентом. Работает желелезка при этом достаточно хитро. Внутри самой колонки крутится маленькая языковая модель, настроенная на распознавании одной из стартовых фраз. Основано на проекте Micro wake word
С завода в колонку пролиты три модели — с фразами Okay Nabu, Hey Jarvis и Hey Mycroft. Нужная выбирается из интерфеса
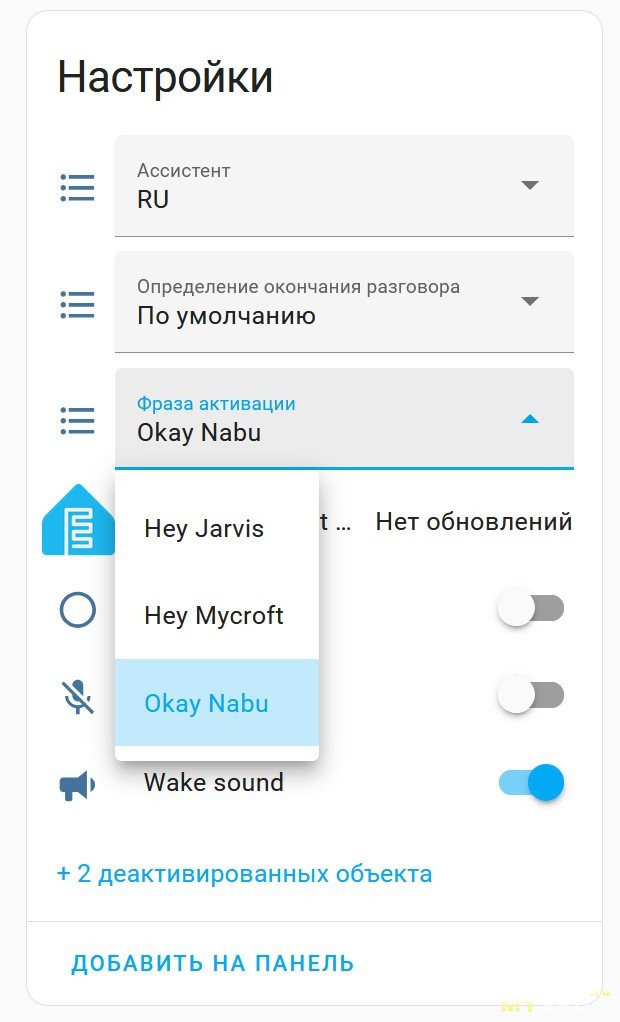 Но т.к. прошивка открытая, ничто не мешает её пересобрать, добавив что-то, натренированное другими людьми(это форк оригинальной репы с моделями если что) или даже натренировать свою. Безграничный простор для пердолинга, всё как мы любим)
Но т.к. прошивка открытая, ничто не мешает её пересобрать, добавив что-то, натренированное другими людьми(это форк оригинальной репы с моделями если что) или даже натренировать свою. Безграничный простор для пердолинга, всё как мы любим)
Работает эта система прям отлично, идеального английского произношения не требует, можно спикать фром йор харт с диким русским акцентом — и всё будет ОК, слышит прекрасно, причём с нескольких метров.
Дальше, как только встроенная модель срабатывает — колонка становится тупой проксёй и стримит аудиопоток на сервер, где и происходит преобразование речи в текст(whisper), обработка команд(home assistant) и преобразование ответа в голос(piper). Здесь и далее контейнеры с whisper и piper крутятся на Orange Pi Zero 3, рядом с самим HA и ещё несколькими сервисами. Можно оценить быстродействие.
Команда на включение таймера работает околоидеально.
Заткнуть сигнал можно либо нажатием кнопки на корпусе, либо повторным произнесением стартовой фразы(что с точки зрения внутренней логики действия полностью аналогичные)
С другими действиями… сложнее. В теории, можно включать\выключать любые устройства в HA, по совпадению по полному наименованию, по типу устройства, по пространству и т.п. На английском всё довольно неплохо, но к сожалению русская языковая модель на текущий момент достаточно бедна и не совсем понимает, что такое эти ваши падежи и склонения. Поэтому рассчитывать можно только на полное совпадение. Проще всего произнести несколько раз некую команду, в отладке языковой модели посмотреть, что же оно такое нараспознавало и добавить несколько синонимов к нужному устройству. Например как-то так)))
 С музыкой тоже не всё гладко. Во первых, сама по себе колонка звучит достаточно паршиво, на mp3 320 отчётливо слышны хрипы на высоких и почти полное отсутствие низких частот.
С музыкой тоже не всё гладко. Во первых, сама по себе колонка звучит достаточно паршиво, на mp3 320 отчётливо слышны хрипы на высоких и почти полное отсутствие низких частот.
Если понизить громкость — становится получше, но такое, громкости там и так немного
(кстати, регулировка громкости выполнена суперски — слизана со старых айподов, да ещё и со светодиодной индикацией. Очень стильно и приятно)
Впрочем, никто не мешает подключить колонку к нормальным стерео динамикам через миниджек и получить вполне пристойный звук.
Во вторых — HA в принципе не особо заточен как провайдер музыки. Обходится скриптами.
Сама колонка пробрасывается в HA как универсальный медиаплеер, который может воспроизвести любой звук из любого источника. Создаём скрипт, который реализует эту команду
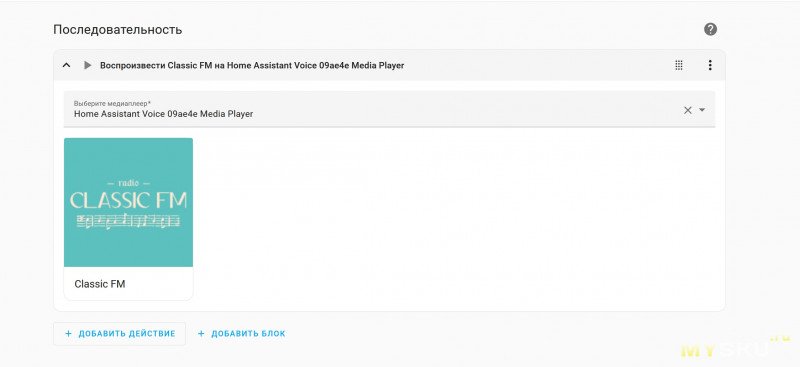 Аналогично навешиваем ему синонимы
Аналогично навешиваем ему синонимы
 И вуаля — оно делает вид, что умное и работает)))
И вуаля — оно делает вид, что умное и работает)))
Ну и так в целом со всеми «навыками». Есть куча заранее созданных блюпринтов, но они все заточены под английский, беглым поиском я под великомугучий ничего не нашёл. Приходится костылить врукопашку.
Выводы. Для людей, которые избегают завязываться на облачные сервисы(а те, кто не избегал, сейчас сильно-сильно страдают в связи с деятельностью ГРЧЦ) — штука почти безальтернативная. Да, можно сделать самопал, но качество и стабильность его работы будет под большим вопросом. Лично у меня оно срабатывало со второго раза на третий, здесь же, если модель на этом слове училась — почти 100% успеха. Если нет — всё уже хуже, но как минимум whisper в принципе перестал выдавать результат обработки «громкая музыка»(это он так тонко намекает, что ничего не расслышал). Шумодав и нормальные микрофоны решают. В остальном же штука не для всех, большинство граждан предпочтут купить колонку с какой-нибудь алисой и не морочиться, и я их прекрасно понимаю. Но в моём доме алис, алекс и прочих сири никогда не будет, поэтому лично я с удовольствием повозился(хоть и не уверен, что буду реально пользоваться).
Ну и следует так же понимать, что Preview Edition в названии фигурирует не просто так — по сути сейчас в продаже бета версия железки, которая может кардинально поменяться или вообще исчезнуть из продажи, если не взлетит. В общем — штука всё ещё для энтузиастов и любителей повозиться, хоть и сделал огромный шаг в сторону простоты и дружелюбности настройки. Спасибо за внимание!
UPD. Дополнение про VOSK
Попробовал прикрутить другой движок распознавания речи, конкретно модель vosk-model-small-ru-0.22
Из коробки она работает ощутимо хуже чем whisper, добавляет лишние предлоги и междометия, нещадно склоняет слова, не преобразует числительные в числа, и т.п.
НО!
Для этого движка есть возможность настроить ограничение используемых фраз по шаблонам — и это прям кардинально меняет дело. Распознавание становится чётким, набивать десяток синонимов для разных приборов больше не надо, ну и вишенкой на торте — на той же Orange Pi Zero 3 VOSK крутится ощутимо шустрее чем whisper, процесс распознавания занимает секунду-полторы. Всем советую, очень крутая тема.
В чём собственно прикол железки. Голосовое управление к HA прикрутили уже достаточно давно, можно с ним разговаривать через телефон, можно через смарт часы. Но вот именно «железной» колонки не было и не было доноров, которые можно было бы перепрошить(либо никто так и не заморочился). Народ городил различного рода самопалы, довольно популярным вариантом был модуль M5 Atom Echo, но работало это всё так себе. Ну и в отличие от — в этой колонке заявлен сдвоенный микрофон и качественный шумодав(забегая вперёд — действительно классно работает, на голову лучше альтернатив). Ну а ещё она стильная и с прикольным управлением. Цена за эту радость, впрочем, немалая. Как обычно, ничего нового.
Игрушка приходит в фирменной коробке из переработанного эко-картония.
Внутри кроме самой колонки нет ничего интересного, только странная наклейка и стопка макулатурыКолонка питается через USB-C, имеет mini jack 3.5 выход на внешние динамики. Сбоку есть тумблер выключения, а снизу — отгибающийся кусок пластика, открывающий доступ к некоему Grove Port — куда можно подключать ряд датчиков платформы M5 Stack:- M5Stack SHT40-BMP280 temperature, humidity, air pressure sensor
- M5Stack PIR motion sensor
- M5Stack SGP30 TVOC, eCO2 gas sensor
- M5Stack BH1750 ambient light sensor
Колонка подключается очень просто. Включаем колонку(диодное кольцо на ней начинает мерцать бело-розовым), открываем на телефоне фирменное приложение HA, Настройки -> Устройства и службы. Вверху списка будет найденная по Bluetooth колонка с предложением её добавить.Жмём, вбиваем Wifi креды, колонка подключается, обновляет прошивку(если есть обновления) и предлагает её донастроить. В теории, дальше всё должно произойти также (next-next-next-готово), но у меня всё пошло немного не по плану и из вариантов мне был предложен только облачный сервис, что разумеется не наш путь.Подозреваю, связано с тем что у меня Core инсталляция HA, которая не поддерживает дополнения, в случае с установкой в виде докер образа либо через HA OS всё должно быть гораздо проще.Затаскиваем контейнеры с whisper и piper в HA Core
Собственно, нам нужно накатить docker и docker-compose
На примере того же Debian
Модель специально заточена под очень слабое железо типа одноплатников(и в целом неплохо на них шевелится). Если развёртывание происходит на взрослом железе — есть и другие варианты моделей
 Вместо ru_RU-ruslan-medium можно прописать ru_RU-dmitri-medium, ru_RU-irina-medium или ru_RU-denis-medium
Вместо ru_RU-ruslan-medium можно прописать ru_RU-dmitri-medium, ru_RU-irina-medium или ru_RU-denis-medium
Но как по мне, руслан — самый адекватный голос)
Послушать семплы можно тут
Также вместо собственного контейнера можно генерить голос через Google Translate, тогда из docker-compose.yaml можно выпилить всё, что касается контейнера piper. Останется так
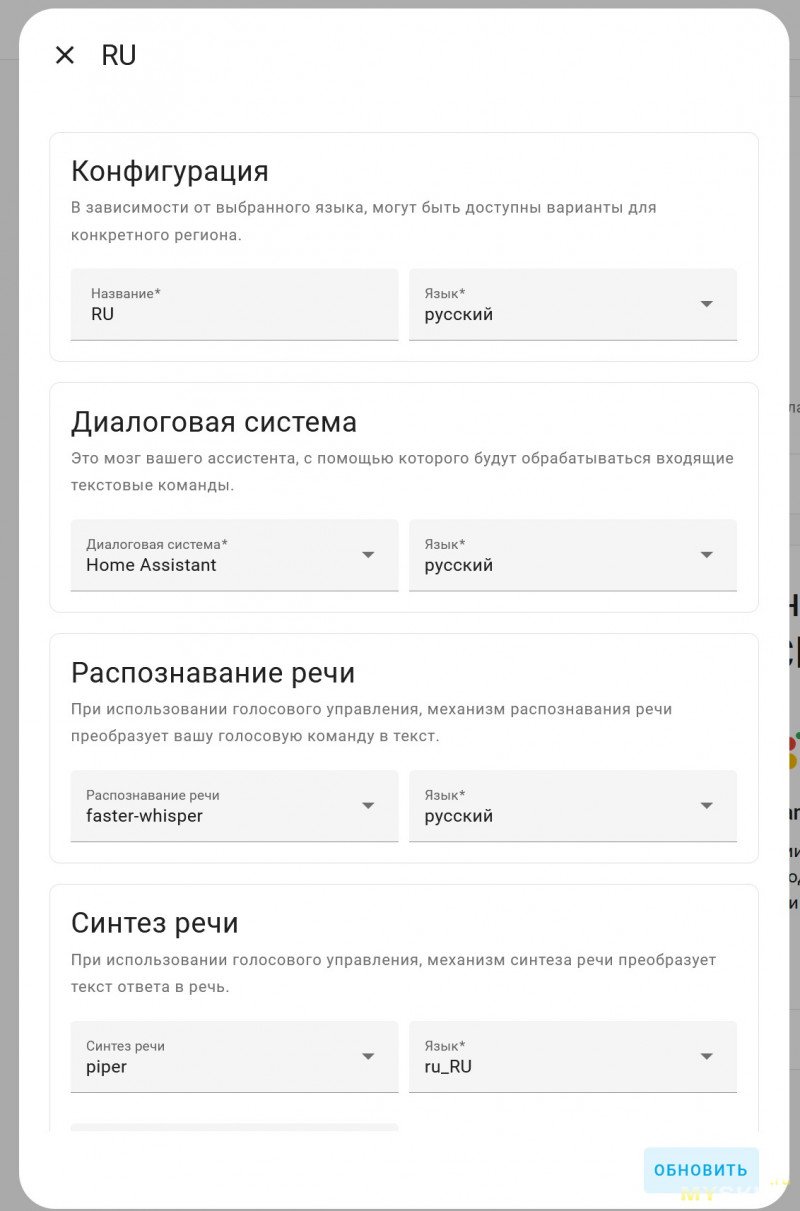
Ну и дальше создаём нового голосового ассистента и прописываем в нём всё, что подняли
На примере того же Debian
sudo apt update
sudo apt install docker docker-compose
sudo mkdir -p /opt/whisper_piper/piper-data
sudo mkdir -p /opt/whisper_piper/whisper-data
cd /opt/whisper_piper
version: '3.4'
services:
whisper:
container_name: whisper
security_opt:
- apparmor=unconfined
image: rhasspy/wyoming-whisper:latest
command: --model tiny-int8 --language ru
volumes:
- /opt/whisper_piper/whisper-data:/data
environment:
- TZ=Europe/Moscow
restart: unless-stopped
ports:
- 10300:10300
piper:
container_name: piper
security_opt:
- apparmor=unconfined
image: rhasspy/wyoming-piper:latest
command: --voice ru_RU-ruslan-medium
volumes:
- /opt/whisper_piper/piper-data:/data
environment:
- TZ=Europe/Moscow
restart: unless-stopped
ports:
- 10200:10200
Модель специально заточена под очень слабое железо типа одноплатников(и в целом неплохо на них шевелится). Если развёртывание происходит на взрослом железе — есть и другие варианты моделей
Вместо ru_RU-ruslan-medium можно прописать ru_RU-dmitri-medium, ru_RU-irina-medium или ru_RU-denis-mediumНо как по мне, руслан — самый адекватный голос)
Послушать семплы можно тут
Также вместо собственного контейнера можно генерить голос через Google Translate, тогда из docker-compose.yaml можно выпилить всё, что касается контейнера piper. Останется так
version: '3.4'
services:
whisper:
container_name: whisper
security_opt:
- apparmor=unconfined
image: rhasspy/wyoming-whisper:latest
command: --model tiny-int8 --language ru
volumes:
- /opt/whisper_piper/whisper-data:/data
environment:
- TZ=Europe/Moscow
restart: unless-stopped
ports:
- 10300:10300
sudo docker-compose up
[Unit]
Description=Whisper and piper services
Requires=docker.service
After=docker.service
[Service]
Restart=always
WorkingDirectory=/opt/whisper_piper
# Remove old containers, network and volumes
ExecStartPre=/usr/bin/docker-compose -f /opt/whisper_piper/docker-compose.yaml down -v
# Compose up
ExecStart=/usr/bin/docker-compose -f /opt/whisper_piper/docker-compose.yaml up
# Compose down, remove containers
ExecStop=/usr/bin/docker-compose -f /opt/whisper_piper/docker-compose.yaml down
[Install]
WantedBy=multi-user.target
Ну и дальше создаём нового голосового ассистента и прописываем в нём всё, что подняли
Так или иначе донастраиваем колонку с голосовым ассистентом. Работает желелезка при этом достаточно хитро. Внутри самой колонки крутится маленькая языковая модель, настроенная на распознавании одной из стартовых фраз. Основано на проекте Micro wake word
С завода в колонку пролиты три модели — с фразами Okay Nabu, Hey Jarvis и Hey Mycroft. Нужная выбирается из интерфеса
Но т.к. прошивка открытая, ничто не мешает её пересобрать, добавив что-то, натренированное другими людьми(это форк оригинальной репы с моделями если что) или даже натренировать свою. Безграничный простор для пердолинга, всё как мы любим)Работает эта система прям отлично, идеального английского произношения не требует, можно спикать фром йор харт с диким русским акцентом — и всё будет ОК, слышит прекрасно, причём с нескольких метров.
Дальше, как только встроенная модель срабатывает — колонка становится тупой проксёй и стримит аудиопоток на сервер, где и происходит преобразование речи в текст(whisper), обработка команд(home assistant) и преобразование ответа в голос(piper). Здесь и далее контейнеры с whisper и piper крутятся на Orange Pi Zero 3, рядом с самим HA и ещё несколькими сервисами. Можно оценить быстродействие.
Команда на включение таймера работает околоидеально.
Для тех, кто не смог обойти блокировку ютьюба
На видео я такой произношу «Окай Набу, включи таймер на 15 секунд», а оно берёт и включает, красиво мигая огонёчками
Заткнуть сигнал можно либо нажатием кнопки на корпусе, либо повторным произнесением стартовой фразы(что с точки зрения внутренней логики действия полностью аналогичные)
С другими действиями… сложнее. В теории, можно включать\выключать любые устройства в HA, по совпадению по полному наименованию, по типу устройства, по пространству и т.п. На английском всё довольно неплохо, но к сожалению русская языковая модель на текущий момент достаточно бедна и не совсем понимает, что такое эти ваши падежи и склонения. Поэтому рассчитывать можно только на полное совпадение. Проще всего произнести несколько раз некую команду, в отладке языковой модели посмотреть, что же оно такое нараспознавало и добавить несколько синонимов к нужному устройству. Например как-то так)))
С музыкой тоже не всё гладко. Во первых, сама по себе колонка звучит достаточно паршиво, на mp3 320 отчётливо слышны хрипы на высоких и почти полное отсутствие низких частот. Если понизить громкость — становится получше, но такое, громкости там и так немного
(кстати, регулировка громкости выполнена суперски — слизана со старых айподов, да ещё и со светодиодной индикацией. Очень стильно и приятно)
Впрочем, никто не мешает подключить колонку к нормальным стерео динамикам через миниджек и получить вполне пристойный звук.
Для тех, кто не смог обойти блокировку ютьюба
На видео из колонки звучит лунная соната и делает это довольно хреново. Также показываю, как регулируется громкость.
Во вторых — HA в принципе не особо заточен как провайдер музыки. Обходится скриптами.
Сама колонка пробрасывается в HA как универсальный медиаплеер, который может воспроизвести любой звук из любого источника. Создаём скрипт, который реализует эту команду
Аналогично навешиваем ему синонимыИ вуаля — оно делает вид, что умное и работает)))Для тех, кто не смог обойти блокировку ютьюба
На видео я произношу «Окай Набу, включить музыку», а оно берёт и включает заранее настроенный скрипт с синонимом «Музыку», который запускает проигрывание интернет радио.
Ну и так в целом со всеми «навыками». Есть куча заранее созданных блюпринтов, но они все заточены под английский, беглым поиском я под великомугучий ничего не нашёл. Приходится костылить врукопашку.
Выводы. Для людей, которые избегают завязываться на облачные сервисы(а те, кто не избегал, сейчас сильно-сильно страдают в связи с деятельностью ГРЧЦ) — штука почти безальтернативная. Да, можно сделать самопал, но качество и стабильность его работы будет под большим вопросом. Лично у меня оно срабатывало со второго раза на третий, здесь же, если модель на этом слове училась — почти 100% успеха. Если нет — всё уже хуже, но как минимум whisper в принципе перестал выдавать результат обработки «громкая музыка»(это он так тонко намекает, что ничего не расслышал). Шумодав и нормальные микрофоны решают. В остальном же штука не для всех, большинство граждан предпочтут купить колонку с какой-нибудь алисой и не морочиться, и я их прекрасно понимаю. Но в моём доме алис, алекс и прочих сири никогда не будет, поэтому лично я с удовольствием повозился(хоть и не уверен, что буду реально пользоваться).
Ну и следует так же понимать, что Preview Edition в названии фигурирует не просто так — по сути сейчас в продаже бета версия железки, которая может кардинально поменяться или вообще исчезнуть из продажи, если не взлетит. В общем — штука всё ещё для энтузиастов и любителей повозиться, хоть и сделал огромный шаг в сторону простоты и дружелюбности настройки. Спасибо за внимание!
UPD. Дополнение про VOSK
Попробовал прикрутить другой движок распознавания речи, конкретно модель vosk-model-small-ru-0.22
Из коробки она работает ощутимо хуже чем whisper, добавляет лишние предлоги и междометия, нещадно склоняет слова, не преобразует числительные в числа, и т.п.
НО!
Для этого движка есть возможность настроить ограничение используемых фраз по шаблонам — и это прям кардинально меняет дело. Распознавание становится чётким, набивать десяток синонимов для разных приборов больше не надо, ну и вишенкой на торте — на той же Orange Pi Zero 3 VOSK крутится ощутимо шустрее чем whisper, процесс распознавания занимает секунду-полторы. Всем советую, очень крутая тема.
Процесс закатки контейнера vosk+piper
В целом не сильно отличается от прошлого варианта. docker-compose.yaml будет выглядеть так:
Да, с числительными конкретно так пришлось поморочиться.
Подробнее о том, что тут происходит, можно почитать тут
Ну и всё, дальше всё аналогично. При первом обращении контейнер создаст кеш словаря рядом с ru.yaml, это займёт некоторое время(не увлекайтесь перекрёстными списками, он их преобразует в список линейный и при неаккуратном обращении легко раздувает до нескольких гигабайт), что займёт какое-то время. Дальше будет всё шустро.
На сладенькое, можно ещё прикрутить поверх этого nginx, чтобы сделать балансировку нагрузки между несколькими серверами. Например у меня дома есть относительно мощный сервак, который крутит эту модель ну очень быстро, но периодически бывает сильно занят. И дохлая апельсина, которая включена и относительно свободна 24\7.
Тогда в nginx.conf можно прописать что-то такое
version: '3.4'
services:
vosk:
container_name: vosk
security_opt:
- apparmor=unconfined
image: rhasspy/wyoming-vosk:latest
command: --sentences-dir /data/sentences --correct-sentences --limit-sentences --data-dir /data --model-for-language ru vosk-model-small-ru-0.22
volumes:
- /opt/whisper_piper/vosk-data:/data
environment:
- TZ=Europe/Moscow
restart: unless-stopped
ports:
- 10300:10300
piper:
container_name: piper
security_opt:
- apparmor=unconfined
image: rhasspy/wyoming-piper:latest
command: --voice ru_RU-ruslan-medium
volumes:
- /opt/whisper_piper/piper-data:/data
environment:
- TZ=Europe/Moscow
restart: unless-stopped
ports:
- 10200:10200
sudo su -
mkdir -p /opt/whisper_piper/vosk-data/sentences
cd /opt/whisper_piper/vosk-data
wget https://alphacephei.com/vosk/models/vosk-model-small-ru-0.22.zip
unzip vosk-model-small-ru-0.22.zip
rm vosk-model-small-ru-0.22.zip
sentences:
- "[какая ][сейчас ]погода"
- in: "что там на улице"
out: "погода"
- "(установи|запусти) таймер на ({nums}|{tens1}|{tens2}{nums}) (секунд|секунду|минут|минуту|час|часов|часа)"
- "(установи|запусти) таймер на ({nums}|{tens1}|{tens2}{nums}) (минут|минуту) ({nums}|{tens1}|{tens2}{nums}) (секунд|секунду)"
- "(установи|запусти) таймер на ({nums}|{tens1}|{tens2}{nums}) (час|часов|часа) ({nums}|{tens1}|{tens2}{nums}) (минут|минуту)"
- "(останови|отключи|выключи) таймер"
- "(запусти|включи)[ть] {device} [(в|на) {zone}]"
- "(выключи|отключи)[ть] {device} [(в|на) {zone}]"
- "включи следующ(ий|ую) [трек|песню]"
- "переключи на следующ(ий|ую) [трек|песню]"
- "следующ(ий|ая) (трек|песня)"
- "(включи|верни) (прошл(ый|ую)|предыдущ(ий|ую)) [трек|песню]"
- "переключи на (прошл(ый|ую)|предыдущ(ий|ую)) [трек|песню]"
- "предыдущ(ий|ая) (трек|песня)"
- "постав(ить|ь) [музыку|песню|трек|воспроизведение] на паузу"
- "[при]останов(ить|и) (музыку|песню|трек|воспроизведение)"
- "(возобнови|продолж(и|ай))[ воспроизведение]"
- "(сними|снять) [музыку|песню|трек] с паузы"
lists:
device:
values:
- свет
- вытяжку
- кондей
- кондиционер
- вентилятор
- лампу
- люстру
- ночник
- споты
- музыку
- чайник
- телевизор
- стиральную машину
- отпариватель
zone:
values:
- кухне
- прихожей
- мастерской
- спальне
- кабинете
- туалете
- ванной
nums:
values:
- in: один
out: "1"
- in: одну
out: "1"
- in: два
out: "2"
- in: две
out: "2"
- in: три
out: "3"
- in: четыре
out: "4"
- in: пять
out: "5"
- in: шесть
out: "6"
- in: семь
out: "7"
- in: восемь
out: "8"
- in: девять
out: "9"
tens1:
values:
- in: десять
out: "10"
- in: одиннадцать
out: "11"
- in: двенадцать
out: "12"
- in: тринадцать
out: "13"
- in: четырнадцать
out: "14"
- in: пятнадцать
out: "15"
- in: шестнадцать
out: "16"
- in: семнадцать
out: "17"
- in: восемнадцать
out: "18"
- in: девятнадцать
out: "19"
- in: двадцать
out: "20"
- in: тридцать
out: "30"
- in: тридцать
out: "30"
- in: сорок
out: "40"
- in: пятьдесят
out: "50"
- in: шестьдесят
out: "60"
- in: семьдесят
out: "70"
- in: восемьдесят
out: "80"
- in: девяносто
out: "90"
tens2:
values:
- in: "двадцать "
out: "2"
- in: "тридцать "
out: "3"
- in: "тридцать "
out: "3"
- in: "сорок "
out: "4"
- in: "пятьдесят "
out: "5"
- in: "шестьдесят "
out: "6"
- in: "семьдесят "
out: "7"
- in: "восемьдесят "
out: "8"
- in: "девяносто "
out: "9"
Да, с числительными конкретно так пришлось поморочиться.
Подробнее о том, что тут происходит, можно почитать тут
Ну и всё, дальше всё аналогично. При первом обращении контейнер создаст кеш словаря рядом с ru.yaml, это займёт некоторое время(не увлекайтесь перекрёстными списками, он их преобразует в список линейный и при неаккуратном обращении легко раздувает до нескольких гигабайт), что займёт какое-то время. Дальше будет всё шустро.
На сладенькое, можно ещё прикрутить поверх этого nginx, чтобы сделать балансировку нагрузки между несколькими серверами. Например у меня дома есть относительно мощный сервак, который крутит эту модель ну очень быстро, но периодически бывает сильно занят. И дохлая апельсина, которая включена и относительно свободна 24\7.
Тогда в nginx.conf можно прописать что-то такое
stream {
upstream lb_whisper {
server external.server:10300 fail_timeout=5s;
server localhost:10300 backup;
}
upstream lb_piper {
server external.server:10200 fail_timeout=5s;
server localhost:10200 backup;
}
server {
listen 11300;
proxy_pass lb_whisper;
}
server {
listen 11200;
proxy_pass lb_piper;
}
}
Самые обсуждаемые обзоры
| +49 |
1701
27
|
www.home-assistant.io/voice-pe/
«произношу «Окай Набу, включить музыку», а оно берёт и включает заранее настроенный скрипт с синонимом «Музыку», который запускает проигрывание интернет радио»
Ну или вот этот же скрипт в виде ямльника
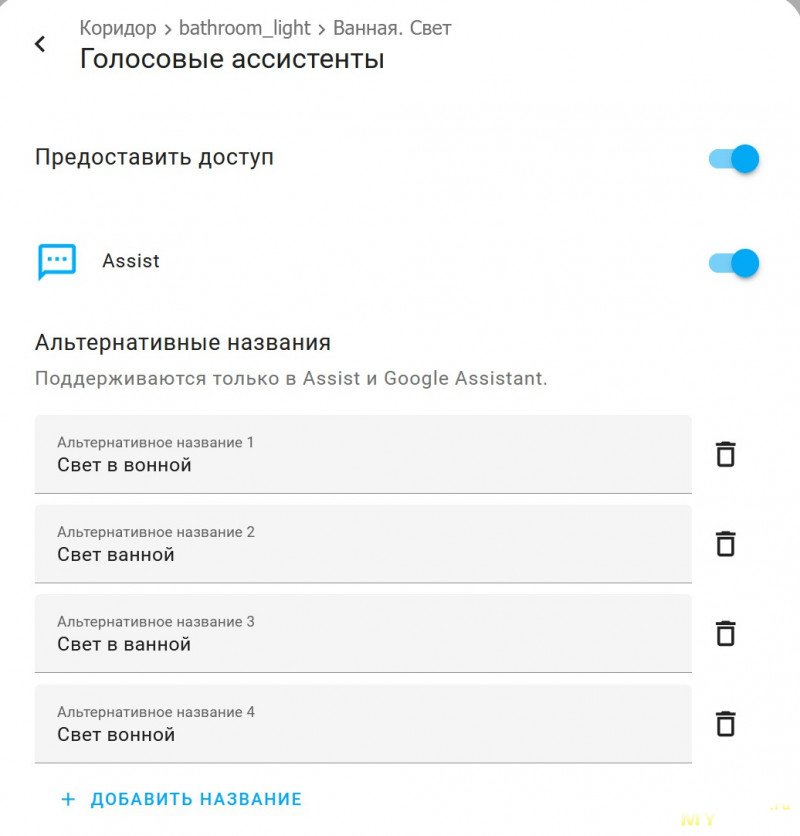
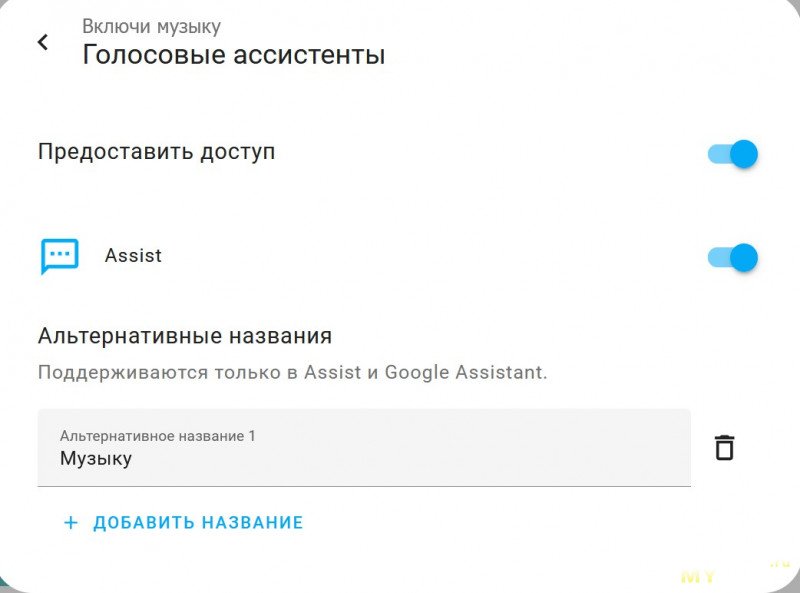
Если что, тут алиас — это не синоним для голосового управления. Чтобы добавить синоним для какого-то объекта, проваливаемся в его настройки и жмём обведённый пункт меню
По факту, на сейчас распознавание английского сильно шагнуло вперёд, и в силу количества носителей языка, и в силу возросших вычислителлных мощностей. Да и сам язык — объективно — проще. Нет падежей, нет склонеений, произношение слов не имеет десятка разных форм с мигающими гласными и прочими такими приколами. Всех сложностей — конечный и детерминированный список неправильных глаголов, с которыми STT движок быстрей всего никогда не столкнётся, т.к. конструкции со всякими хитрыми временами никто в голосовых командах использовать не будет. Может, какой-нибудь эсперанто был бы ещё проще, но кому он реально нужен?
www.youtube.com/watch?v=RTiK8ne2IIc
Если не погружаться в звук, то самодельная колонка будет понимать только когда в неё прямо говоришь, а не из другого конца комнаты под шум раковины.
А припаять шилды к ЕСП и корпус напечатать много умений не надо, да. Ну а если искать готовый аудиопроцессов – так это устройство и найдёте.
У меня периодически возникает желание завандалить Алису/Марусю, вытряхнуть из неё все активные компоненты, а микрофон/динамик/кнопки подключить к своим, той же ESP хотя бы. Если получится, то как раз будет DIY, но с профессионально собранной акустикой.
Алиса: dzen.ru/a/Y-85CdSznj1qLIYD
Маруся: habr.com/ru/companies/vk/articles/565100/
Думаю, основной блин с процессором, памятью, цапоусем и сетевыми чипами бесполезно хакать в домашних условиях, но сделать простой его аналог можно.
Особенно Марусю, которую по слухам закапывают. Вот в таком случае для неё может и коммерциализация такой самоделки имеет смысл. Но я скорее о простом рукоблудстве в качестве хобби.
Или вы о том, как эту штуку включить для плагина, а не в случае вручную запущенного контейнера? Там по идее тоже самое должно быть, видел на скриншотах соотв. переключалку в настройках. К сожалению, у меня core инсталляция HA, в плагины не могу потыкать.
Я всё никак не договорюсь с жабой на поиграться с HA Voice. Алиса и так дома есть — но так и не подключил, ибо не знаю зачем :)
З.Ы. А то и вообще можно на рузене 5500 взять
В теории, да, в новых алисах такой вектор может быть: в конечное устройство загружается локальная модель на нужные кодовые слова и «на материк» уходит только декодированная мякотка в текстовом виде. На практике нужно очень много молчащих ртов на всей цепочке.
Однако себе домой я беру Алисы без нейромодулей, признаюсь.
если через 1 предложение появляется аббревиатура, не упомянутая в тексте ранее?
ведь те, кто в теме и так знают про «кат»)))
/zanuda_mode off